

책소개
사용자 만족 서비스를 위한 최강 솔루션, 웹 최적화
사용자는 개발자가 생각하는 대로 움직이지 않는다. 사용자 요구는 물론이고 해결 방법조차 분명하지 않은 상황에서 유일한 해답은 사용자의 행동이다. 행동을 관찰하고 얻은 통찰에 기반해 가설을 수립하고 새로운 대책을 웹 서비스에 적용하며 최적화를 진행하는 것이다. 이에 도움이 되는 강력한 무기가 바로 통계와 머신러닝이다. 웹 최적화를 통해 머신러닝 세계를 새롭게 보는 눈을 뜨길 바란다.
저자소개
 저자
저자
이쓰카 슈헤이
UX 엔지니어, 크리에이티브 테크놀로지스트. 공학 박사. 1989년 이바라키현 쓰치우라시 출생. 2017년 도쿄대학 공학계 연구과 기술경영전략학 전공 및 박사 과정을 수료했다. 재학 당시부터 다양한 웹 서비스를 구축 및 운영했으며 웹 최적화 연구에 매진했다. 현재 웹과 머신러닝을 융합한 작품 제작에 몰두하고 있다.
역자
김연수
소프트웨어 엔지니어이자 번역가다. ‘나와 주변을 끊임없이 변화시키며 좋은 지식을 전달하는 것’과 ‘스스로 지속할 수 있는 삶’에 관심이 많아 번역을 시작했다. 옮긴 책으로는 『카이젠 저니』, 『알파 제로를 분석하며 배우는 인공지능』, 『파이썬으로 배우는 게임 개발 입문편 & 실전편』, 『다양한 예제로 배우는 CSS 설계 실전 가이드』, 『효율적 개발로 이끄는 파이썬 실천 기술』(이상 제이펍), 『IT, 전쟁과 평화』, 『팀 토폴로지』(이상 에이콘), 『마케팅 성공률을 높여주는 구글 애널리틱스』(이상 위키북스) 등이 있다.
목차
CHAPTER 1 A/B 테스트부터 시작하자: 베이즈 통계를 이용한 가설 검정 입문
1.1 A/B 테스트의 영향
1.2 앨리스와 밥의 보고서
1.3 확률 분포
1.4 베이즈 정리를 이용한 클릭률 추론
1.5 다른 해결책 1: 반복 모으기
1.6 다른 해결책 2: 베타 분포
1.7 사후 분포를 이용한 결단 내리기
1.8 정리
칼럼: 실험 설계의 기본 원칙
CHAPTER 2 확률적 프로그래밍: 컴퓨터의 도움을 받자
2.1 통계 모델 기술과 샘플링 실행
2.2 진정한 리뷰 점수
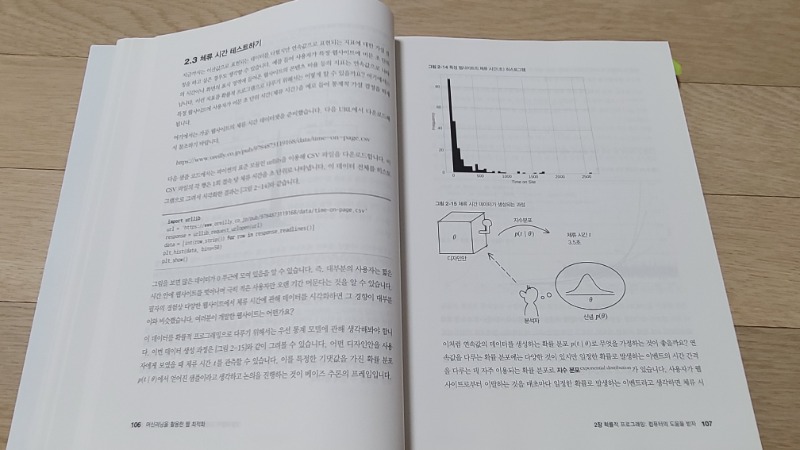
2.3 체류 시간 테스트하기
2.4 베이즈 추론을 이용한 통계적 가설 검정을 하는 이유
2.5 정리
CHAPTER 3 조합 테스트: 요소별로 분해해서 생각하자
3.1 찰리의 보고서
3.2 효과에 주목한 모델링
3.3 통계 모델 수정
3.4 완성한 보고서, 잘못된 모델
3.5 모델 선택
3.6 정리
칼럼: 직교 계획과 웹 최적화
CHAPTER 4 메타휴리스틱: 통계 모델을 사용하지 않는 최적화 방법
4.1 마케팅 회의
4.2 메타휴리스틱
4.3 언덕 오르기 알고리즘
4.4 확률적 언덕 오르기 알고리즘
4.5 시뮬레이티드 어닐링
4.6 유전 알고리즘
4.7 정리
칼럼: 유전 알고리즘과 대화형 최적화
칼럼: 웹 최적화와 대화형 최적화
CHAPTER 5 슬롯머신 알고리즘: 테스트 중의 손실에도 대응하자
5.1 소박한 의문
5.2 다중 슬롯머신 문제
5.3 .-greedy 알고리즘
5.4 시뮬레이티드 어닐링 .-greedy 알고리즘
5.5 소프트맥스 알고리즘
5.6 톰슨 샘플링
5.7 UCB 알고리즘
5.8 에렌의 질문에 대한 답변
5.9 정리
칼럼: 최적 슬롯 식별 문제
CHAPTER 6 조합 슬롯머신: 슬롯머신 알고리즘과 통계 모델의 만남
6.1 다시 찰리의 보고서
6.2 선형 모델과 일반화 선형 모델
6.3 MCMC를 슬롯머신에 사용하기
6.4 베이즈 선형 회귀 모델
6.5 LinUCB 알고리즘
6.6 정리
칼럼: 개인화에서의 응용
CHAPTER 7 베이즈 최적화: 연속값의 솔루션 공간에 도전하자
7.1 마케팅 회의
7.2 베이즈 최적화
7.3 가우스 과정
7.3.1 커널 트릭
7.4 컴퓨터와 대화하며 최적의 색 찾기
7.5 GP-UCB 알고리즘
7.6 GP-TS 알고리즘
7.7 응용 시 주의할 점
7.8 에렌의 질문
7.9 정리
칼럼: 베이즈 최적화를 대화형 최적화에 응용하기
CHAPTER 8 앞으로의 웹 최적화
8.1 단기적인 평가와 장기적인 평가
8.2 솔루션 공간 디자인
8.3 웹사이트 이외의 응용
APPENDIX A 행렬 연산 기초
A.1 행렬 정의
A.2 행렬의 합
A.3 행렬의 곱
A.4 행렬의 전치
APPENDIX B 로지스틱 회귀상에서의 톰슨 샘플링
B.1 베이즈 로지스틱 회귀
B.2 로지스틱 회귀 톰슨 샘플링
출판사리뷰
웹 최적화에 머신러닝을 도입한 국내 최초의 책
우리는 일상에서 접하는 대부분이 인터넷과 연결된 세계에 살고 있습니다. 사용자에게 최고의 경험을 제공하기 위해서는 빠른 변화와 다양성에 적극 반응하고 적응하는 것이 중요합니다. 그런데 사용자는 웹 서비스 개발자가 예상하는 것과 다르게 반응하고 행동합니다. 사용자가 원하는 것이 무엇인지 직접 물어봐서 알 수 있다면 좋겠지만, 이는 무척 어려운 일이며 사용자 자신이 원하는 것을 정확하게 알고 말한다는 보장도 없습니다.
이때 A/B 테스트로 대표되는 최적화 기술이 유용합니다. A/B 테스트에서 숫자로 나타난 사용자의 선택뿐만 아니라 그 이면에 숨겨진 데이터를 가설 검증에 활용해 더 나은 최적화 설계를 수행할 수 있게 해줍니다. 이제까지 베일에 가려져 있던 이 중요한 기술을 체계적으로 정리한 책은 국내에 없었습니다. 이 책은 통계학과 머신러닝이라는 수학적 방법을 이용해 최적화를 설명하고 코드를 통해 구체적으로 알기 쉽게 정리했습니다. 웹 최적화에 관한 고민을 이 책이 덜어줄 것입니다.
독자리뷰
최근 회사에서 A/B 테스트에 대한 필요성을 많이 이야기하고 있습니다. 그래서 구글 애널리틱스에 대한 책이라던지, 관련 서적을 몇권 찾았는데요. 문제는 아직 손도 못댔다는 겁니다. '핑계없는 무덤이 없다'하지만, 뭘하느라 그리 시간을 못내는지, 8월 이후로는 시간이 한달 단위로 없어지는 걸, 느껴오고 있습니다.
결국 A/B 테스트에 대해서 전무 한 상황에서 이 책을 읽게 되었습니다.
저자는 10년전 "버븐"이라는 서비스가 "인스타그램"이 되었던 이야기로 이 책을 시작합니다. 버븐을 만든 사람들은 레스토랑이나 쇼핑몰 사진을 찍어 공유하는 서비스로 "버븐"을 만들었다고 하는데요. 사용자들이 "버븐"에서 잘 쓰는 기능은 그것이 아니었습니다. 사용자들은 사진의 필터링과 공유를 주로 썼거든요. 버븐의 개발자들은 사용자들이 원하는 서비스가 무엇인지 이해하기 시작했고, 딱 필요한 기능만을 남겨둔 "인스타그램"을 만들어서, 말그대로 대박을 터뜨렸습니다.
A/B 테스트는 사용자가 무얼 원하는지 알아내는 테스트 방식입니다. A와 B를 보여주고 뭘 좋아하는지 알아보는 거죠. 그래서, A/B 테스트에 대한 책은 대부분 A/B테스트를 하는 테스트 프로그램에 대해서 설명하는 책이 됩니다. 넣어보고, 결과를 알아보는 식으로 상황을 보정해 나가는 것, 이외에 A/B테스트에 대해서 알필요가 없으니까요.
그런데, 이 책은 그렇지 않습니다. A/B 테스트를 위해 필요한 수학과 확률을 다루거든요. 책을 읽으면서, 두가지 생각이 머릿속을 떠나지 않았습니다. '정말 꼼꼼하게 잘 설명했다'와 '그런데 난 뭔 말인지 못알아듣겠다' 였습니다.
어떤 분야를 공부하든, 그 분야 일을 하려면 결국은 알아야 하는 이론들이 있습니다. 이 책은 A/B 테스트에서 그 부분을 수학적으로 설명하고 있는 겁니다. 정말 수포자인 제가 읽기도 쉽게 설명하고 있습니다. 문제는 제 두뇌 초입에 탑재되어 있는 필터 입니다. 수학적인 이론으로 판단되면 걸러 버리는 필터 ...
스티브 잡스는 "소비자들이 원하는 제품을 만들었다면 매킨토시를 만들지 않고, 더 빠른 도스 터미널을 만들었을 거라"고 이야기 했다고 합니다. 소비자들은 사실 자기가 원하는게 뭔지 모른다는 의미인데요. 그건, 소비자들이 기술적인 부분에서 잘 모르기 때문입니다. 매킨토시가 나오기전, 소비자들은 GUI라는 개념이 있는지 몰랐습니다. 그러니 스티브 잡스에게 "더 빠른 도스 터미널"을 만들어 달라고 할 밖에요.
그런데 만약 기술을 맛볼 수 있는 기회가 소비자들에게 주어진다면 어떨까요? 그럼, 스티브잡스에게 매킨토시를 만들어 달라고 했을 지도 모릅니다. A/B테스트는 소비자에게 기술을 맛볼 기회를 제공해주는 가장 훌륭한 도구입니다. 이 책은 그걸 이론적으로 설명한 책이고요. 따라서 A/B 테스트로 서비스를 개선하려는 사람들이라면, 이 책은 훌륭한 안내가 될 수 있을 겁니다.
다만, 저같은 수포자가 읽은뒤, 모르는 부분을 따라가기는 좀 힘들듯합니다. 참고문헌이 모두 영어와 일본어로 되어 있어서요. 책을 여러번 읽으면서 이해하는 쪽을 택하는 게 좋을 것 같았습니다. 책 차체 내용은 충분하니까요.
저는 A/B 테스트에 대해 모아두었던 책들을 찾아 읽어보고, 다시 읽어봐야 할것 같습니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
2021년 올해의 책리뷰 / 머신러닝을 활용한 웹 최적화 / 한빛미디어

이 책은 UX 엔지니어, 크리에이티브 테크놀로지스트이자, 공학 박사인 일본인 이쓰카 슈헤이가 집필한 책입니다. 머신러닝을 활용한 웹 최적화를 참고하고 공부하기 위해서는 파이썬 문법, 선형대수, 미분과 적분 정도의 수학적 지식이 선행되어야 합니다. 그래야 잘 이해할 수 있게 됩니다. 이러한 지식을 가지고 있는 웹 엔지니어, 웹 마케팅, 머신러닝에 흥미있는 사람들에게 추천할 만한 책입니다.
아래와 같이 총 8장으로 구성되어 있습니다.
1. A/B 테스트부터 시작하자 : 베이즈 통계를 이용한 가설 검정 입문
2. 확률적 프로그래밍 : 컴퓨터의 도움을 받자
3. 조합 테스트 : 요소별로 분해해서 생각하자
4. 메타휴리스틱 : 통계 모델을 사용하지 않는 최적화 방법
5. 슬록머신 알고리즘 : 테스트 중의 손실에도 대응하자
6. 조합 슬롯머신 : 슬롯머신 알고리즘과 통계 모델의 만남
7. 베이즈 최적화 : 연속값의 솔루션 공간에 도전하자
8. 앞으로의 웹 최적화
통계학을 정말 잘해야 할 것 같은게 확률 관련 수식과 그래프가 많이 보입니다. 이해가 쉽게되도록 생성되는 과정들을 그림으로 표현하고 있습니다. 그래도 수학적 수식을 이해하는 건 좀 어려운 듯 합니다. 특히, 수학 확률 과정에서 베이즈, 가우스를 좀 알면 좋을 듯 합니다. 마지막 부분 APPENDIX에 행렬, 베이즈 로지스틱 회귀을 자세히 설명해주고 있습니다.
웹 사이트는 이미지, 텍스트 버튼 등 여러 요소가 조합되어 이루어지는데, 이러한 요소들을 어떠한 조합으로 표현하고 싶은지에 대하여 테스트할 수 있도록 설계하고 데이터를 분석하는 부분에 대해서 다룹니다. 또한 어떠한 색상을 사용하면 좋을지에 대한 분석 알고리즘을 다룹니다. 그 밖에 웹 사이트에 대한 다양한 문제를 머신러닝 알고리즘을 통해 분석하여 웹을 최적화할 수 있도록 확률을 통해 보여줍니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."

현재는 모든 사업들이 대부분 디지털화되어 가고 있어서 웹사이트나 앱에서 상춤 구입, 시장 조사 등을 처리하고 있습니다. 그리고 단순히 공통적인 마케팅이 아닌 사용자의 구매 상품이나 자주 찾는 검색어 등의 데이터를 수집하여 개인 맞춤형 마케팅 전략을 펼치고 있는 추세입니다. 여기서 사용되는 기술 중 웹사이트 최적화 기술은 '현대의 카이젠'이라고 말해도 과언이 아닌 숨겨져 있는 매우 중요한 기술입니다.
최적화 기술이란 제품의 두가지 버전을 준비하여 사용자의 선호에 맞춰 최적화 하는 것인 개인 맞춤형 제품을 만들어 나가는 기술입니다. 이러한 기술은 GAFA(Google, Apple, Facebook, Amazon)를 비롯하여 대기업은 물론 네트워크 기업이나 실리콘 밸리의 스타트업에서도 매일 빠른 속도로 이뤄지고 있을 만큼 중요하고 강력한 기술입니다.이처럼 이 기술은 매우 중요하지만 베일에 가려져 있어서 체계적으로 정리한 책은 많지 않습니다.
제가 이 책을 선택한 이유는 이 기술을 수학적 배경에서 설명하고 코드를 통해 구체적으로 알기 쉽게 정리하여 나타내고 있기 때문입니다.
이 책의 특성은 수학적 방법(통계학과 머신러닝)을 이용해 웹 최적화 테스트의 결과를 분석하고, 그 결과를 최적화에 적용하는 방법을 담고 있습니다. 그저 최적화 테스트에서 숫자로 나타난 사용자의 선택뿐만 아니라 그 이면에 숨겨진 데이터를 가설 검증에 활용해 보다 나은 최적화 설계를 수행할 수 있게 도움을 줄 수 있는 내용을 담고 있습니다.
이 책은 통계학 또는 머신러닝에 입문하고자 하는 웹 엔지니어나 웹 마케팅 관련 담당자 및 웹 마케터 그리고 머신러닝 응용, 특히 사람과의 상호 작용에 대한 응용에 흥미가 있는 분들이 읽으시면 도움이 많이 되실 내용을 가지고 있습니다.
요즘 대기업에서는 디지털화 되어 가는 사업추세에 맞춰 마케팅 전략을 웹이나 모바일 앱에서 사용자들이 자주 검색하는 제품 이름 및 제품 유형 데이터를 수집하여 시장 조사 및 소비자들의 선호도를 조사하는 추세입니다. 또한 공통적인 데이터 뿐만 아니라 소비자별로도 데이터를 조사하여 개인 맞춤형 마케팅 전략을 펼치고 있습니다. 이처럼 최적화 기술은 비즈니스적으로 매우 중요한 기술이기 때문에 개발자나 이 기술을 잘 활용하여 마케팅 전략을 펼칠 수 있는 사람을 대거 채용하고 있는 추세입니다.
구성
Chapter 1: A/B테스트부터 시작하자: 베이즈 통계를 이용한 가설 검정 입문
Chapter 2: 확률적 프로그래밍: 컴퓨터의 도움을 받자
Chapter 3: 조합 테스틔 요소별로 분해해서 생각하자
Chapter 4: 메타휴리스틱: 통계 모델을 사용하지 않는 최적화 방법
Chapter 5: 슬롯머신 알고리즘: 테스트중의 손실에도 대응하자
Chapter 6: 조합 슬롯머신: 슬롯머신 알고리즘과 통계 모델의 만남
Chapter 7: 베이즈 최적화: 연속값의 솔루션 공간에 도전하자
Chapter 8: 앞으로의 웹 최적화
Appendix A: 행렬 연산 기초
Appendix B: 로지스틱 회귀상에서의 톰슨 샘플링
파트별로 나누어 봤을때 1~3장은 최적화 기술의 기초 및 요소별 분석방법에 대해 설명하고 있고 4장은 통계 모델을 사용하지 않고 최적화 하는 방법에 대해, 5~7장은 슬롯머신 알고리즘을 통한 연속값 최적화에 대해 8장은 최적화 기술의 앞으로의 방향과 응용되어질 분야에 대해 설명하고 있습니다.
그리고 맨뒷장은 행렬 연산 기초나 로지스틱 회귀상에서의 톰슨 샘플링 같은 수학적 방법에 대한 이론내용이 있으니 한번쯤 보시는 것을 추천드립니다.
개인적인 생각으로 학습은 1부터 시작해야하는 시니어이신 분들께서는 1장부터 시작하시면 좋을것 같고 어느정도 머신러닝에 대해 경험이 있으신 분들(머신러닝에 대해 기초적인 지식은 숙지하고 있다.)은 1장을 가볍게 보시면서 최적화에 대한 이론을 숙지하신 후에 2장부터 시작하시면 좋을듯 싶습니다. 그리고 현재 머신러닝에 대해 지식이 어느정도 풍부하시거나 현직에서 사용하시면서 마케팅이나 프로젝트를 위해서 머신러닝을 학습하시는 분들 역시 2장부터 시작하시면 좋을듯 싶습니다.
그리고 개인적으로 약간의 단점이 내용구성부분에서 기초적인 부분은 간단히 하고 더 많은 현업에서의 케이스에 대한 내용이나 실습 부분이 좀더 많았으면 더 좋았을것 같다는 아쉬움이 있습니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
책은 A/B테스트를 소개하면서 여기에 들어간 각종 확률 분포, 덧셈정리, 곱셈정리, 이항 분포 등에 대해 차근차근 설명이 들어간다. 통계 쪽을 좀 알고 있다면 무난히 넘어갈 수 있지만 만약 그런 부분들을 보충해야 된다면 기초 단계부터 설명이 들어가므로 따라가면 충분히 이해할 수 있다.
이후 2장에서는 확률적 프로그래밍을 좀 더 쉽게 하기 위한 PyMC3를 소개한다.
3장에서는 3개 이상의 선택지가 조합으로 묶일 때 어떻게 테스트할지에 대한 내용이다. A/B테스트는 2가지 경우에 대해서만 집중했기 때문에 현실에서는 주로 더 많은 선택 조합이 나올 가능성이 높다.
3장에서는 여러 가지 다양한 조합을 찾고 교호 작용에 대해서도 소개를 한다. 여기까지 읽었을 때 책의 비중이 주로 통계적 스킬에 대부분을 할애하고 있다는 것을 알았으니 참고하면 좋겠다.
4장에서는 메타휴리스틱 방법을 소개한다. 어떤 통계적 모델을 사용하기보다는 일반적으로 좋다고 알려진 지식을 휴리스틱적으로 풀어가는 것을 말한다. 답이 딱히 정해지지 않았는데 문제를 풀어야 되는 상황에서 이런 메타휴리스틱적 방법은 충분히 고려해볼 만하다. 언덕 오르기 알고리즘이 코드로도 제시되어 있으므로 한번 연습하는 것도 좋겠다.
이밖에 슬롯머신 알고리즘, 조합 슬롯머신 등 실제 비즈니스에서 최적화를 위한 여정을 이어갈 때 일어날 수 있는 상황을 앞에 도입 부분에서 상황 설명을 하고 이를 각 해결방법으로 설명한 뒤 이론이나 더 알면 좋을 이론 내용으로 부가설명하는 것이 이 책의 공통적인 부분이다. 전반적으로 통계쪽 내용의 비중이 높으니 참고하면 좋겠다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."




웹 최적화.
기획자, 디자이너, 개발자라면 항상 고민하고 있는 화두이다.
아무리 좋은 기획과 최신 기술로 개발을 했더라도 사용자의 호감을 살 수 없다면 무용지물이다.
그렇기에 최대한 사용자 반응을 고려한 기획을 하고 디자인을 하고 개발을 한다.
그럼에도 원하는대로 사용자가 사용하지 않을 수도 있고, 의도와는 다르게 사용자에게 불편을 주기도 한다.
이런 실수를 줄이기 위해 늘 웹 최적화 방법에 대해 고민을 한다.
그 방법 중 하나가 'A/B 테스트'이다.
만족시켜야 하는 요구 사항은 그것을 만족시키는 방법조차 분명하지 않은 상황에서의 유일한 해답은 사용자가 실제로 취하는 행동입니다.
사용자의 행동이야말로 사용자의 체험이 결과로 표출된 것이기 때문입니다.
...
개발자는 사용자의 행동을 관찰함으로써 얻은 통찰에 기반해 가설을 수립하고, 새로운 대책을 웹 서비스에 적용합니다.
개발자는 그 행동의 변화를 관찰함으로써 가설을 검증하고 새로운 통찰과 가설을 이어나갑니다.
A/B테스트의 존재 이유와 목적에 대해 설명하고 있다.
바로 '가설 검증'이다.
사용자가 어떤 것을 더 좋아하는지를 사용자 행동을 통해 유추하고 확인하여 서비스를 개선하는 것이다.

이 책은 '웹 최적화'와 '머신러닝'을 함께 다루고 있다.
개발자들은 두 번 이상 작업할 것에 대해서 자동화하기를 원한다.
그리고 사용자 반응에 대한 정확하고 빠른 유추를 원한다.
그에 대한 가장 좋은 방법 중 하나가 머신러닝의 도입이다.
이 책의 구성은 아래와 같이 이루어져 있다.

웹 최적화 방법에 따른 순서대로 어떻게 머신러닝을 도입할 수 있는지를 보여주고 있다.
사용자 요구 분석을 위해서 필요한 것이 통계이다.
그렇기에 이 책은 A/B테스트에 대해 수학적 배경은 물론이고, 그것을 구현하기 위한 코드도 제공하고 있다.
머신러닝을 구현한 코드를 보여주는 책들은 많다.
하지만 그 코드에 대한 이론적 배경을 이해하지 못한다면 확장은 물론이고, 응용 또한 힘들다.
그렇기에...솔직히 말하면 통계적 지식이 전무하다면 이 책을 쉽게 이해할 수 없다.
어느 정도의 수학적 이론-많은 이들이 곤혹스러워 하는 미,적분-에 대한 이해가 있어야 수월하게 읽어나갈 수 있다.
나 또한 이 책을 보면서 몇 번씩 수학 공식에 대한 이해를 하기 위해 인터넷을 뒤졌다.

오랫만에 시그마, 인터그랄을 보면서 느낀 반가움과 당혹감이란...
웹 최적화에 대한 자동화를 고민하고 있다면, 머신러닝에 대한 관심이 있다면 두 마리 토끼를 한꺼번에 잡을 수 있는 책이다.
머신러닝 전문가에 대한 요구는 많지만 그 요구를 만족시켜주는 개발자가 적은 이유를 알 수 있었다.
오랫만에 머리를 아프게 하는 책을 보았다.
부족함이 많음을, 앞으로도 배울 것이 많다는 것을 새삼 느꼈다.

개발을 하다 보면 늘 겪는 문제는 개발자의 의도대로 사용자가 행동하지 않는다는 것이다.
사용자의 패턴과 행동을 기반으로 모든 프로젝트의 동기와 시작점이 돼야 하지만
정작 개발자들은 당장의 눈앞의 코드들을 내 의식에 맞춰서 작성하기 마련이다.
그런 의미에서 이 책은 그동안 개발자들이 간과하고 있던 사용자의 행동을 관찰하고,
그 관찰을 통해서 얻은 데이터를 기반으로 하여 현재 상황과 앞으로의 비전에 맞춰 새로운 대책을 웹 서비스에 적용하여 웹 최적화를 이루는 목표를 삼고 있다.
이에 가장 백그라운드가 되는 머신러닝과 딥러닝을 기반으로 한 웹 최적화는 개발자의 개발 활동에 있어서 길라잡이의 역할을 톡톡히 할 것이라 생각한다.

Author: 이쓰카 슈헤이 지음 / 김연수 옮김
출판사: 한빛미디어
Score /5: ⭐️⭐️⭐️⭐️⭐️
[이 책의 대상 독자]
요즘 머신러닝에 대한 인기는 엄청나다. 이에 편승해서 머신러닝에 대한 책들도 같이 쏟아지다시피 하고 있다.
독자입장에서는 선택의 권리가 늘어나기 때문에 더할나위 없다. 하지만 대부분 기본 도서가 일반적이다.
이런 상황에서 머신러닝을 활용한 웹 최적화는 실제 머신러닝을 활용하는 방법을 보여줬다.
이 책의 장점은 수식 및 적절한 그림으로 인해서 이해도를 높여주며, 무엇보다도 웹 사이트 최적화를 여러 관점으로 나눠보고 각 관점마다 적용할 수 있는 머신러닝 방법을 체계적으로 진행 및 실습을 할 수 있다.
두번째 이 책의 장점은 기본 이론에 충실하게 접근해서 문제를 해결한다는 것이다. 신규 트렌드가 아니라 기존 기본서를 통해서 배우거나 많이 들은 이론등을 문제해결에 사용하는 모습을 충실히 보여준다.
하지만 이 책은 쉽지않다. 처음부터 이 책으로 머신러닝에 대한 입문은 힘들것이다.
하지만 어느정도 기본서를 보고 나서 다음 스텝으로 이 책을 보기를 추천한다. (기본적으로 확률 및 통계에 대한 이해가 있다면 그냥 봐도 됨)
※ 이 책은 한빛미디어의 지원으로 작성된 글입니다

책에서 다루는 머신러닝 알고리즘은 통계학에 대한 공부가 어느정도 되어있지 않다면 굉장히 낯설수 있습니다. 수학과는 거리가 멀다면 알고리즘에 대한 이해가 쉽지 않습니다. 사전 지식이 받쳐주지 않는다면 알고리즘에 대한 이해는 좀 더 다양한 자료를 구글링을 통해 보고 필요하다면 수학 공부도 하면서 이해한다면 좋을 것 같습니다. 책에서 다루는 알고리즘들에 대해 컨셉과 배경 등을 설명하지만 공식에 대한 이해는 사전 지식어 없다면 힘들 것입니다.
수학에 대한 지식이 부족하여 수식을 이해하려고 하기보다는 해당 알고리즘의 목적이나 컨셉, 적용 상황 그리고 구현 코드 위주로 살펴볼 수 밖에 없었습니다. 수학을 싫어하는 웹 개발자가 보기에는 난해할 수도 있을 것 같았습니다. 내용 자체는 흥미로웠고, 다루는 내용들이 추후 서비스 개발할 때, 대시보드를 만들거나 여러 알고리즘을 검색할 때 참고할만한 내용들입니다.
이 책은 학부생때 통계학을 어느정도 공부한 웹 개발자들이 보기에 적합해보이는 책입니다. 웹에 적용되는 머신러닝 알고리즘의 이야기가 주이기에 웹에 대한 깊은 이해보다는 통계학에 대한 지식이 더 많이 요구됩니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."

> 책의 구성 및 내용
이 책은 340 page입니다.
책의 내용은 웹사이트 상호작용간의 통계를 머신러닝을 통해 분석하는 내용에 가깝습니다.
예를 들어
전자상거래 사이트의 사용자별 구입점수를 최대화한다거나,
사용자의 체류시간을 최대화 하고자 할때
특정요인을 설정하여 해당 요인에 대한
통계를 통해 웹 서비스를 최적화 시킨다는 게 해당 책의 요지 입니다.
개발자로서 최적화라기보다 기획자나 마케터로서 인터페이스의 최적화에 대한
설명이 주로 되고 있습니다.
대부분의 내용이 데이터 가설을 통한
데이터 사이언스라고 불리는 영역으로 표현할 수 있을 것 같습니다.
기획이나 마케팅쪽 경험은 없고 개발이나 운영관리에 경험이 있다보니
초반에 설명되는 오바마선거 캠프의 웹사이트 조합 이야기나
마이크로소프트 Bing 의 검색 결과 페이지 링크 텍스트의 색 변경테스트 등
실제 인터페이스와 관련된 테스트들은 처음 접해보아 생각보다 흥미로웠고
사이트 방문에 대한 데이터를 통해 가설과 결론을 얻는 것이 재미있었습니다.

확률에 대한 계산이 매우 어려운 내용은 아니지만,
대학 졸업이후 오랜만에 다시보게되는 확률 계산들이
익숙해지는데 조금 시간이 걸리기도 하였습니다.
읽으면서 많이 느낀 점은
확률,통계에 익숙하신 분이 책을 좀 더 쉽고 빠르게 읽을 수
있겠다는 생각이 들었습니다.
1장을 읽는 동안에는 내용들이 기본적인 확률, 통계가 주된 내용이여서
대체 머신러닝은 언제나오는 건가? 라는 생각이 많이 들었습니다.
3장 이후부터 머신러닝을 적용하는 내용이 보이기 시작합니다.
여러가지 웹사이트 최적화를 위한 factor 들을 놓고 어떤것이 영향이 큰지에 대해
분석하는 부분도 있습니다.
4장은 통계모델을 사용하지 않는 최적화방법으로 메타 휴리스틱을 설명하고 있습니다.
이전에 전체 통계를 통해 최적을 찾아간다면 4장은 하나씩 관련 요소를 정복해 나가면서
최적을 찾아가는 방법을 설명하고 있습니다.
8장은 지금까지 설명해온
단기적인 평가(즉각적인 반응에 따른 최적화방법)와
장기적인 평가가 다름을 설명하는데, 매우 흥미로웠습니다.
신규사용자와 반복사용자를 구분해서 평가하는 것들도 새로워서 재밌게 읽을 수 있었습니다.
기억에 남는 글 중에 하나는
"웹디자인에서 단 한 줄의 코드를 이용해서 표시하는 요소를 전환할 수 있지만,
사용자의 인식에는 그이상의 영향이 있음을 항상 의식해야 합니다"
라는 말이 기억에 남았습니다.
> 장점
> 단점
> 책읽기 필요사항
통계/확률, 머신러닝에 대한 기본지식
> 추천 독자
웹 엔지니어, 웹 마케터, 머신러닝응용 흥미있는분

> 정보
저자: 이쓰카 슈헤이
옮긴이: 김연수
출판사: 한빛미디어
가격: 34,000원
전체 페이지: 340페이지
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."

임의의 사용자가 접속하는 웹은 사전에 사용자의 선호도나 성향을 분석하기 어렵다. 많은 웹 페이지들이 고객의 성향에 맞춘 정보를 노출하기 위해 다양한 노력을 기울이고 있다. 특히 전자상거래 또는 OTT 서버스 등이 고객의 클릭을 유도하거나 고객 맞춤형 정보를 제공하기 위해 특별한 노력을 기울이고 있다.
웹 설계자나 개발자가 아무리 노력을 해도 사용자를 100% 이해하고 만들수는 없을 것이다. 하지만 사용자의 행동을 관찰하고 분석한다면 좀 더 사용자에게 맞는 최적화를 진행할 수 있을 것이다. 이를 위해 필요한 도구가 머신러닝과 통계이다.
기존 다양한 노력은 통계 기반으로 최적화를 진행해 왔다고 생각한다. 물론 수치로 표현할 수 있는 통계를 통계 최적화를 할 수는 있지만 다양한 상황을 분석하기 위해서는 머신러닝을 접목하는 것이 필요한 기술적인 요소일 수 있다.
이 책은 크게 8개의 장으로 구성된다. 1장에서는 베이즈 통계를 이용한 가설 검증을 시작하는 형태로 A/B 테스트를 설명한다. A/B 테스트는 웹 최적화를 위해 많이 사용하는 방법 중의 하나이다. 이 장을 통해 확률분포와 베이즈 정리, 다양한 분포에 대해 이해를 높일 수 있다.
2장에서는 확률적 프로그래밍에 대해 설명한다. 데이터가 생성되는 과정을 통계 모델의 형태로 기술하면구체적인 문제를 추상화하고, 다른 대상 및 컴퓨터와 공유할 수 있게 된다. 이 통계 모델을 확률적 프로그래밍 언어(PPL)로 기술하면 컴퓨터를 통해 사후 분포를 추론해 다양한 통계량을 계산하고 출력할 수 있다. 확률적 프로그래밍이란 통계 모델을 소스 코드로 기술해서 자동으로 추론을 수행하는 구조를 의미한다.
3장에서는 조합 테스트에 대해 설명한다. 다양한 요소가 조합되어 이루어진 웹사이트에서 하나의 요소를 업데이트한 디자인뿐만 아니라 여러 요소를 변경한 디자인에 대해 테스트할 경우가 종종 있다. 이 경우 실험을 어떻게 설계하고 데이터를 분석할 수 있는지 소개한다.
이 이외에도 메타휴리스틱, 슬롯 머신 알고리즘, 조합 슬롯머신, 베이즈 최적화, 앞으로의 웹 최적화 등 다양한 주제에 대해 설명한다. 웹 최적화를 위해서 서로 다른 알고리즘을 사용해서 다양한 문제에 대한 방안을 분석할 수 있다. 특히 웹 최적화를 바탕으로 설명한 알고리즘과 기술들이 다른 영역에서도 사용 가능하다는 것을 일부 보여주고 있다. 물론 몇가지 조건이 있지만 그 조건만 만족한다면 다양한 영역에서 최적화 문제를 분석할 수 있을 것으로 본다.
이론적인 설명과 함께 수식이 제시되고 python을 이용한 테스트를 보여준다. 물론 appendix에 수식 이해를 위해 필요한 행렬 연산 기초와 톰슨 샘플링에 대해 설명하면서 이해를 높이고자 하지만 전반적인 수식의 이해를 어려운 것 같다. 하지만 수식을 이해하지 못한다고 해서 그 배경이나 개념을 이해하기 어려운 것은 아닌 것 같다.
웹 최적화를 고민하고 방안을 검토 중이라면 이 책에서 셜명하는 다양한 방법론들이 많은 도움이 될 것이라고 생각한다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
머신러닝을 활용한 웹 최적화 라는 제목만을 보고 웹에 머신러닝을 적용하여 좀 더 빠르게, 편리하게, 효율성 있게 하는 방법에 대한 책이라고 생각했었다.
책의 요점은 나에게는 알고리즘에 대한 설명처럼 느껴졌다. 다양한 머신러닝 방법들을 이용해서 결론적으로 A/B TEST에서 살아 남을 수 있는 웹페이지를 구상해보는 것이 목표처럼 느껴졌다. 파이선 코드가 있지만, 사실 Futurewarning이 생각보다 많이 나고, Jupyter환경에서는 쉽지는 않았다. 최신의 코드인줄 알았는데 조금은 오래된 코드이어서 중간중간 코드를 고쳐나가야 하는 것이 좀 안좋았다. 차라리 Colab을 사용하는 것을 추천한다.
다양한 코드를 통해서 베이즈 추론, 마르코프 연쇄 몬테카를로 알고리즘, 메타휴리스틱등 다양한 알고리즘을 설명하는 것은 좋지만. 사전에 머신러닝에 대해서 상당한 지식을 갖추지 않으면 사실 읽기가 좀 어려운 부분이 있었다.
사실 웹에서 현업에 종사하는 개발자라면 도움이 되겠지만. 교사인 나는 크게 와닿지는 않은듯 하다.
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
통계는 항상 어렵기만 합니다. 모든 이론이 그러하듯 개념적인 부분을 읽고 익혀도 실무에서 어떻게 적용해야 할지, 이 통계가 무엇을 말하는지 의미를 파악하고 이를 통해 변화를 주는 것은 더 어렵습니다. 이렇게 막연하던 통계 이론이 드디어 내 것이 되는 책이 바로 '머신러닝을 활용한 웹 최적화' 입니다. 그저 쉽게 접할 수 없는 내용일 것 같아 호기심에 선택했는데, 통계가 여전히 어려운 저에게는 정말 큰 도움이 되는 책이었습니다.
2008년 대통령 선거에서 오바마 진영은 웹사이트의 이미지와 버튼의 조합을 각각 다르게 설정함으로써 어떠한 디자인과 문구가 사람들로 하여금 더 많은 가입을 하게 하는지 실험을 합니다. 그리고 그 결과를 통해 얻어진 디자인을 적용함으로써 큰 효과를 거두었습니다. 실무자들이 기대를 걸었던 오바마의 연설 영상보다 오히려 가족과 함께 촬영한 사진이 더 인기가 좋았고, 이 영상과 Join us, Sign Up 과 같은 일상적인 문구가 아닌 Learn More 문구의 버튼을 함께 표시했을 때 가입률이 가장 높았다고 합니다. 무척이나 어려워 보이는 '머신러닝을 활용한 웹 최적화'는 이렇게 흥미로운 주제로 시작됩니다. A/B테스트를 통해서 훨씬 많은 클릭율을 이끌어내고 이를 통해 더 효과적인 의사 결정을 할 수 있도록 가장 기본적인 통계 이론부터 이를 파이썬으로 분석하고, 최적의 조합을 찾아내기 위한 다양한 알고리즘을 소개합니다. 또한 무척 어려운 이론과 공식들을 다루고 있지만 해당 이론을 설명할 때는 무척 가볍게 시작하며, 벡터의 의미와 같은 가장 기본적인 내용부터 설명을 해 주기에 의외로 어렵다는 느낌을 받지 않고 읽을 수 있었습니다.
제목처럼 내용이 가벼운 책은 아니지만 위와 같이 흥미로운 이야기와 회사에서 실제로 웹사이트를 운영하며 부딪히는 문제를 해결해가는 스토리로 진행되고 있어 생각보다 어려움을 느끼지 못하고 읽게됩니다. 통계 책을 보면서 막연하게만 느껴졌던 이론들이 살아 움직이는 느낌입니다. 그만큼 실무에 무척 도움이 되지만, 책의 내용을 충분히 익히기 위해서는 스토리처럼 등장하는 통계이론들을 공책에 정리하면서 한 번 더 정확히 공부하면 좋을 것 같습니다. 그렇게 정리하고 나면 다른 어떤 책보다도 더 현실감있는 통계를 익히고 이를 실제 업무에 적용할 수 있을 것 같습니다.




"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."

웹을 최적화했을 경우와 최적화하지 않았을 경우 결과의 차이를 알 수 있는 가장 좋은 예로 미국 오바마 전 대통령의 선거 홍보 웹 사이트 최적화를 들 수 있겠다.
이 책에서는 웹을 최적화하는데 머신러닝을 활용하여 확률적이고 과학적인 방법을 제시하고 있다. 이제는 머신러닝이 적용되지 않는 곳이 없다고 할 수 있겠다.
이 책의 구성을 간단한 도형으로 나타내면 아래의 그림과 같다.
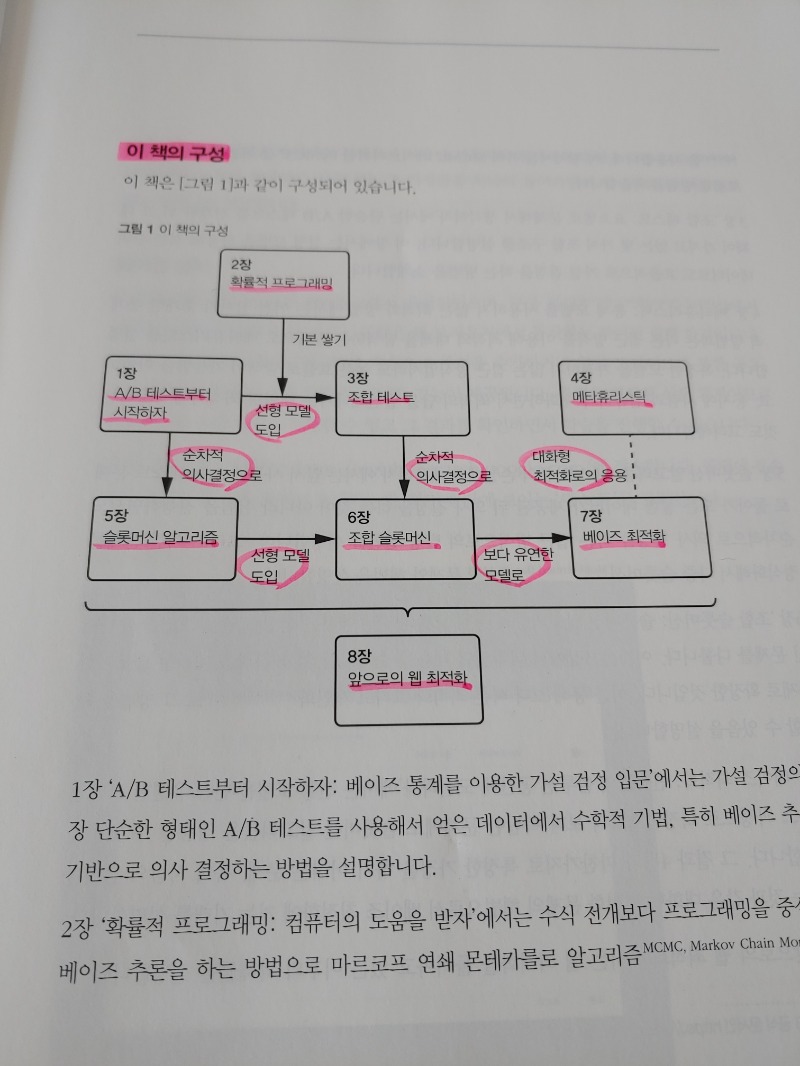
이 책에서 이용한 파이썬 및 라이브러리 버전은 다음과 같다.
1장 A/B 테스트부터 시작하자:
베이즈 통계를 이용한 가설 검정 입문

각종 확률과 관련된 용어들의 의미와 베이즈 정리를 알 수 있다.
2장 확률적 프로그래밍: 컴퓨터의 도움을 받자

통계 모델을 확률적 프로그래밍 언어로 기술하면 컴퓨터가 사후 분포를 추론해 다양한 통계량을 계산해서 출력할 수 있다.
3장 조합 테스트: 요소별로 분해해서 생각하자

여러 요소의 조합으로 이루어진 웹사이트의 A/B 테스트를 생각하는 장입니다.
요소의 조합에 의해 만들어지는 교호 작용에 대해서 설명하고 있습니다.
교호 작용이란 여러 요소를 조합함에 따라 나타나는 효과를 의미합니다.
4장 메타휴리스틱: 통계 모델을 사용하지 않는 최적화 방법

5장 슬롯머신 알고리즘: 테스트 중의 손실에도 대응하자


6장 조합 슬롯머신: 슬롯머신 알고리즘과 통계 모델의 만남

7장 베이즈 최적화: 연속값의 솔루션 공간에 도전하자

8장 앞으로의 웹 최적화

이 장에서는 아래과 같은 내용들을 다루고 있습니다.
부록 A에서 행렬 연산 기초라는 타이틀로 행렬 정의부터 각 행렬들과 행렬의 합, 곱, 행렬의 전치까지 이 책에서 설명한 계산을 이해하기 위해 필요한 최소한의 연산을 모아서 설명합니다.








먼저 <머신러닝을 활용한 웹 최적화>라는 귀한 책을 보내 주셔서 고맙습니다.
개인적으로 이번 리뷰를 통해서 경험하기 쉽지않고 시간이 아깝지 않은 참 좋은 리뷰였습니다.

미국대통령 선거에서 오바마가 공식 웹사이트에서 여러이미지와 버튼의 조합중
조합의 등록률을 살표본결과 가족과 함꼐 찍은 이미지와 learn more 이라고 적힌 버튼의 조합이 가장 많은 등록률이 높았다고 한다.
이처럼 작은 변화가 웹사이트에 큰 영향을 끼치는 영향에 대해 이책은 방향을 제시하는 책이라 볼수있다.
이책은 머신러닝에 대한 기초적인 이해와 파이썬에 대한 이해는 알고있어야 이해할수 있을거라고 본다.
1장에서는 머신러닝에 대해나 이론적인 내용을 주로 다루고 있다.
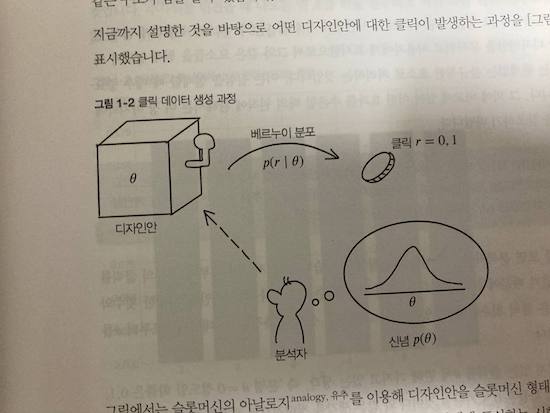
# 0이상 1이하의 범위를 1001개로 분할한 배열 thetas를 준비한다.
import numpy as np
thetas = np.linspace(0, 1, 1001)
print(thetas)
#가능도 함수 likelihood를 작성한다.
likelihood = lambda r: thetas if r else (1 - thetas)
#사후부포는 가능도 함수와 사전함수의 곱이 합계가 1이 되도록 정규화 한다.
def posterior(r, prior):
lp = likelihood(r) * prior
return lp / lp.sum()
#각 theta 가 같은 확률을 갖도록 확률을 나눕니다.
p = np.array([1 / len(thetas) for _ in thetas])
print(p)
#베이즈 추론을 한다. 클릭이 한번 일어났을때 r =1이 주어졌을때의 사후분포를 계산한다.
p = posterior(1, p) # 클릭
print(p)
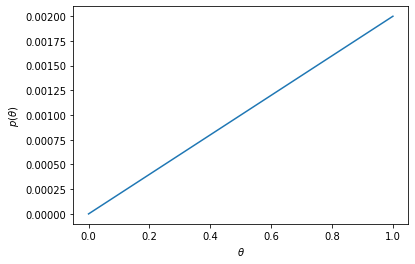
#맵플롯립은 그래프를 그리기 위한 모듈이다.
from matplotlib import pyplot as plt
#가로축에는 thetas 세로축에는 p를 전달한다.
plt.plot(thetas, p)
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p(\theta)$')
plt.show()
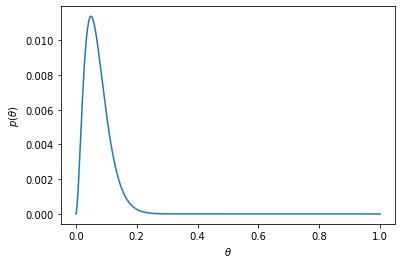
clicks = 2
noclicks = 38
p = np.array([1 / len(thetas) for theta in thetas])
for _ in range(clicks):
p = posterior(1, p)
for _ in range(noclicks):
p = posterior(0, p)
plt.plot(thetas, p)
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p(\theta)$')
plt.show()
시각화 과 0.05 부근으로 폭이 넓어지는 곡선이 생겼다.
조금씩 따라해보면서 이해해고 있는데 생각보다 내용이 쉽지는 않았다.
하지만 생소한 또하나의 분석기법이 될것같아 해당분야에 관심이 있는 사람이라면
머신러닝을 활용한 또하나의 분야를 파악해보는 계기가 될 것 같다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
웹개발자로 산지 20년이 넘었다. 개발하면서 이것저것 느낀점이 많지만 어떻게 사용자 최적화하여 만들까에 대한 고민도 많이 했다.
늘 하는거지만 다른 사이트를 참고하고 다른 사람들이 적용한 UX 를 보면서 어떻게 저렇게 할 수 있을까? 라는 물음을 가질 수 밖에 없었다.
단순 UX적인 측면보다, 속도면에서도 어떻게 하면 더 빠른 웹사이트를 만들 수 있을까 라는 생각을 늘 하고 살았던것 같다.

이제 개발에서 좀 멀어지면서 이러한 고민들이 거의 내 머리속에서 지워지는 상태인데, "머신러닝을 활용한 웹사이트 최적화" 라는 책을 보면서,
어? 정말? 저게 돼?라는 생각으로 이책을 신청하게 되었다. 하지만, 이책에서는 웹사이트 성능 최적화는 다루지 않고 있으며,
다양한 통계모델을 적용한 가설의 검증을 하는 방법에 대해 설명을 하고 있다.
이를 위해 다양한 이론과 이러한 이론을 적용하는 방법적인 예시 그리고 이것들을 검증하는 방법에 대해 잘 설명하고 있다.
어찌보면 검증 방법은 개발자가 만들어야 하는것이지만 개발 내용은 UI/UX 디자이너에게 도움을 주는 그런 내용이라고 할 수 있다.
점점 나이가 들면서 시니어 개발자 혹은 PM역할을 하면서 기획자가 좋은 서비스를 기획할 수 있는 근거를 만들어 내는 방법에 좀 더 가까운 책이라고 할 수 있을거 같다.
이러한 기법을 잘 활용하면 좋은 사이트와 안좋은 사이트를 구별하는 좋은 논문 주제거리가 될 듯 하다.
개인적으론 상당히 재미 있는 책중에 하나가 될듯 하나, 이 책을 읽은 독자들은
책 맨뒤에 소개된것 처럼 웹 최적화를 통해 머신러닝 세계를 새롭게 보는 눈을 뜰수 있는 계기가 될 수 있을듯하다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
책을 읽기 전에는 성능 최적화 또는 검색 엔진 최적화 등의 최적화를 예상하고 들어갔지만, 책에서는 초기부터 해당 내용들은 포함되지 않는다고 단언하고 진행된다. 대신 웹에서 진행될 수 있는 다양한 테스트 예를 들어, A/B 테스트, 체류 시간 테스트, 조합 테스트 등에 통계와 머신러닝을 곁들여 함께 소개한다. 이 책을 읽으며 이런 UI/UX 부분들에도 다양한 테스트가 존재함과 동시에 머신러닝을 이용해 테스트 결과값을 분석하고 더 나은 방향으로 나아가기 위한 지표로 활용되고 연구되어 있다는 것에 감명을 받았다.
성능에만 치중되어 있던 그간의 시선을 유저 사용성과 우리가 원하는 결과를 위한 UI/UX 설계에 대한 이야기들을 볼 수 있었다. 확실히 통계 모델이나 머신러닝 모델에 딥하게 들어가면 살짝은 정신을 못차릴만 하지만, 흥미로운 이야기들과 함께라면 충분히 완독 할 수 있을 것이다!
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
#머신러닝 #웹최적화 #AB테스트 #메타휴리스틱 #베이즈최적화 #베이즈추론 #가설검증 #다중슬롯머신 #MAB #실용통계
사용자에게 어떤 콘텐츠를 보여줘야 할지 고민될 때 어떻게 해야 할까? 예전에는 내부 의사결정자들에게 보고를 하고 결정했었다. 하지만 이제는 실제 사용자 반응을 기반으로 웹사이트 최적화를 진행할 수 있다. 이러한 데이터 기반의 의사결정을 방법론인 그로스 해킹 마케팅이 보편화되면서 A/B테스트를 진행하는 경우가 많아졌다.
실력 있는 마케터라면 A/B테스트로 대표되는 웹 최적화 테스트 실험 환경을 잘 설계하고, 결과를 제대로 분석할 수 있어야 한다. 안 그러면 과학적 실험을 한다는 착각 하에 잘못된 의사결정을 내릴 수도 있다. 그런 의미에서 어려운 통계지식을 실무자 관점에서 쉽게 설명해 주는 책이 나와서 정말 반가웠다.
이 책의 저자 이쓰카 슈헤이는 통계의 기본도 모르던 웹 엔지니어였다. 하지만, 사용자에게 더 나은 경험을 제공하겠다는 목표로 A/B테스트를 하면서 수리적인 가설 검증 방법을 스스로 연구하면서 터득했다. 이렇게 비전공자가 실무를 진행하면서 익혔던 주요한 통계 개념을 정리해 줬다는 점에서 매우 실용적이다.
이 책의 주요 독자는 '통계학이나 머신러닝에 입문하고 싶은 웹엔지니어'와 '웹 마케팅을 담당하는 마케터'이다. 그밖에도 머신러닝을 실무적으로 응용하는 방법에 관심이 있거나, 사용자와의 상호작용 데이터를 해석하는 방법에 흥미가 있는 분들에게도 유익할 것이다.
책의 주요한 목차를 훑어보면 아래와 같다.
[챕터 1] A/B 테스트부터 시작하자: 베이즈 통계를 이용한 가설 검정 입문
- 베이즈 추론을 기반으로 의사결정하는 방법과 실험 설계의 기본 원칙을 설명한다.
[챕터 2] 확률적 프로그래밍: 컴퓨터의 도움을 받자
- 마르코프 연쇄 몬테카를로 알고리즘을 사용해서 프로그래밍을 중심으로 베이즈 추론을 하는 방법을 소개한다.
[챕터 3] 조합 테스트: 요소별로 분해해서 생각하자
- A/B테스트 전개 후 그 대책이 가지고 있는 몇 가지 조합 구조를 설명한다. 선형 모델을 사용해 적은 수의 데이터로도 효율적으로 가설 검정을 하는 방법을 소개한다.
[챕터 4] 메타 휴리스틱: 통계 모델을 사용하지 않는 최적화 방법
- 특정한 모델을 가정하지 않는 접근 방식일지라도 높은 효율로 탐색이 가능함을 확인하고, 동시에 사람과 컴퓨터가 대화하면서 최적의 답을 발견해나가는 대화형 최적화 방안을 제시한다.
[챕터 5] 슬롯머신 알고리즘: 테스트 중의 손실에도 대응하자
- A/B테스트가 끝난 후에 의사결정을 하는 것이 아니라, 실험을 진행하면서도 순차적으로 의사 결정을 하는 발상 전환의 다중 슬롯머신 문제와 해법을 제시한다.
[챕터 6] 조합 슬롯머신: 슬롯머신 알고리즘과 통계 모델의 만남
- 순차적인 의사결정을 내리는 선형 모델을 도입한 슬롯머신 문제를 다룬다. 이는 보다 빠른 최적화, 개인화로 확장될 수 있음을 설명한다.
[챕터 7] 베이즈 최적화: 연속 값의 솔루션 공간에 도전하자
- 선형 모델을 한층 유연한 모델인 가우스 과정으로 확장함으로써 보다 복잡한 문제에도 슬롯머신 알고리즘을 적용할 수 있음을 보여준다. 그 결과 메타 휴리스틱 해법으로 베이즈 최적화에 거는 기대를 설명한다.
[챕터 8] 앞으로의 웹 최적화
- 웹 최적화로 해결되지 않은 남아있는 과제들에 대해서 설명한다.
이 책의 특징은 기본 개념을 분절화하여 각각을 쉽게 이해시킨 다음, 그다음 개념을 하나씩 얹어가는 설명 방식을 취하고 있다. 그래서, 잘만 따라가면 개념을 이해하기가 수월하다.
이 중에서도 가장 큰 도움이 되었던 부분은 [챕터 6] 6.5 LinUCB 알고리즘에 대한 설명이었다. 최근에 모두의연구소 BRS(Bandit Recommendation System) Lab에서 LinUCB 알고리즘을 공부했지만 잘 이해되지 않았다. 그러나, 이 책의 개념 분절화 방식을 통해서 쉽게 이해할 수 있었다. 예를 들면, 기댓값이 나타내는 '유망함'에 분산이 나타내는 '불확실함'을 추가하면 선형 회귀 모델 상의 UCB 알고리즘, 즉 LinUCB 알고리즘을 구상할 수 있음을 쉽게 이해할 수 있게 되었다.
또한 각 챕터의 맨 앞장에 '마케팅 회의'라는 섹션을 두어서, 독자들의 흥미를 유도하고 있다. 지금 챕터에서 설명하고자 하는 주요 개념이 실무에서 어떤 경우에 활용할 수 있는지 구체적으로 설명해 주고 있다. 이런 점에서 실제로 업무를 하는 웹 엔지니어와 웹 마케터 입장에서는 벌어진 상황이 실제 상황과 유사하므로 몰입이 잘 될 것이다. 또한 이를 풀어나가는 과정도 친근하게 설명해 주고 있으므로 쉽게 따라가면서 이해도를 높일 수 있다.
가장 좋았던 부분은 [챕터 8] 8.1 단기적인 평가와 장기적인 평가 부분이었다. 현실에서 단기 지표와 장기 지표의 충돌은 자주 발생한다. 그러므로, 장기적인 지표 개선을 위해서 단기 지표를 희생한다는 결정을 하더라도 이를 통해 장기적인 지표가 개선된다는 예측을 할 수 있는지가 관건이다. 이렇게 항상 고민되는 단기 지표와 장기 지표의 충돌 문제와 이에 대한 해결 방안 제시는 정말 신선했다. 이 문제를 해결한 논문의 저자들은 과거 100개 이상의 실험 결과를 이용해 단기적으로 측정할 수 있는 지표로부터 장기적인 광고 클릭률을 예측하는 머신러닝 모델을 구축했다고 한다. 이 머신러닝 모델을 도입하면 단기적으로는 수익성이 낮아질지 모르나 장기적으로는 좋은 효과를 가진 대책을 선택할 수 있게 된다.
마지막으로 인상적이었던 부분은 [챕터 8] 8.1.1 반복 사용자를 고려한 최적화 부분이었다. A/B테스트 의사결정이 내려져서 웹 서비스의 인터페이스를 바꾸기로 결정할 때, 우리가 간과하기 쉬운 점이 있다. 바로 기존의 반복 사용자들이 지불해야 하는 새로움에 대한 학습 비용이다. 신규 사용자들에게는 이전에 학습된 것이 없기 때문에 결정이 쉽게 날 수 있지만, 기존의 반복 사용자들에게는 익숙해진 불편함을 버리고, 낯선 편리함을 채택해야 한다. 이 결정이 옳은 것일까? 이 부분에 대한 솔루션으로 웹 최적화를 강화 학습으로 보고, 기존 사용자가 가진 상태를 다루는 기법을 제안하고 있다. 정말 신박한 아이디어라고 생각되었다.
이 책을 통해서 기존에 A/B테스트를 진행하면서 내가 뭘 모르고 있는지도 모르고 어설프게 알고 있는 방식의 실험만 반복했었다는 것을 알게 되었다. 저자의 다양한 경험을 통해서 스스로 공부하고 정리한 내용을 통해서 제대로 체계를 잡을 수 있어서 많은 도움이 되었다. 앞으로 다양한 실험 설계를 통해서 웹 최적화를 제대로 해 보고 싶은 웹 엔지니어와 웹 마케터라면 이 책을 천천히 정독하고 실제 업무에 적용해 보기를 추천한다.

잘 팔리는 상품에는 분명 그만한 이유가 숨어 있다. 잘 팔리려면 상품 자체의 기능, 디자인, 퀄리티가 좋아야 하는 것은 당연한 이야기일 것이다. 그런데 똑같은 품질, 똑같은 기능의 제품인데도 누군 대박 나고, 누군 쪽박을 차는 모습을 보면, 꼭 상품만 좋다고 잘 팔리는 것은 아니라는 것을 알 수 있다. 여기에는 마케팅도 중요한 이유가 된다.
편의점에 있는 가득 줄지어 놓여 있는 물건을 보면, 그냥 마구 놓은 거 같지만, 놓이는 높이, 위치, 시간대 등을 다 고려한 복잡한 마케팅 행위의 산물이다. 누군가에게 하나라도 더 많이 선택되기 위해서, 시각적, 심리적, 경제적 연구와 오랜 판매 경험을 담은 결과인 것이다. 전에는 관심 없었던 물건을 인기품으로 올리기도 하고, 누군가의 머릿속에 오래 남게 하여 어떻게든 판매로 이끄는 것이 마케팅인 것이다.
아니, 웹 최적화, 머신러닝, 프로그램 관련 책 이야기를 하는데 왜 뜸금없이 마케팅 얘기를 하나 할 것이다. 만일 이렇게 생각한다면, '머신러닝을 활용한 웹 최적화'라는 책이 뭘 하기 위해 최적화를 하는지 전혀 모르고 하는 소리다. 이 책에서 말하는 웹 최적화는 화면에 더 빨리 그려주고, 서버나 DB에 전송하는 것을 빠르게 최적화하는 것을 말하는 것이 아니다. 웹에 어떤 사진, 어떤 버튼, 어떤 문구, 어떤 색상을 해야 사람들이 더 관심을 가지고, 모여드는가를 얘기하고 있는 책이기 때문이다. 즉 앞에서 말한 마케팅 얘기처럼 뭔가 잘 팔리고, 잘 나가는 웹 사이트, 목적을 효과적으로 잘 살린 웹을 구축하는 방법을 말하고 있는 책인 것이다.
누군가는 '버튼, 문구, 컬러? 이것은 웹디자이너가 하는 것이 아닌가?' 말할 수도 있다. 웹 디자인에 관심이 있는 분이라면, 어떻게 디자인하는 것이 좋은 디자인인지 잘 나와 있는 유명한 책도 보았을 것이다. 그러나 '머신러닝을 활용한 웹 최적화'는 '이렇게 해야 보기 좋고, 보색으로 배치하고, 폰트 크기는 얼마, 구성은 어떻게' 하는 디자인 측면에서 웹 최적화를 말하는 책이 아니다. 여기서는 인공지능, 머신러닝에 활용되는 각종 알고리즘, 베이즈와 기존 통계적인 기법을 사용하여, 수치적으로 값을 구해 어떤 디자인이 사람을 끌게 만드는 디자인인지 객관적으로 알아내는 방법을 알려준다.

웹 디자인이나 프로그램 화면 디자인을 해본 분이라면, UI의 중요성과 함께 디자인만 예쁘거나 멋지게 만들었다고, 그게 좋은 프로그램이 되는 것이 절대 아닌 걸 잘 알고 있을 것이다. 문제는 이 디자인이 잘됐는지 잘못됐는지 알 방법이 없다는 게 큰 문제다. 내가 보기에 잘 됐다고 해서, 사용자들이 다 좋아한다는 보장을 어떻게 할 수 있을까? 게다가 결정된 디자인으로 인해, 내가 손해를 보고 있는지, 이익을 보고 있는지 알 길이 없다. 디자인 조금만 바꿔도 12.5% 이상의 클릭이 증가할 수도 있는데도 말이다. 이 책에 나와 있는 내용을 보면, 2013년 Bing의 검색 결과 화면에 약간의 텍스트 색 정도만 바꿨는데도 연간 1천만 달러 수익 증가를 실현했다고 한다. 웹의 최적화는 이익 최적화와 일맥상통하다는 것을 보여준다.
더 이상 개인의 감이나 어쭙잖은 심리학 적용 디자인과는 바아바이해야 한다. 과거에는 이런 것들이 어쩔 수 없이 행해졌지만, 인공지능 시대를 맞이해서, 이제 웹에도 이런 기술이 도입되어야 하는 것이다. 물론 구글, 아마존, MS 같은 IT 선도 기업들은 이미 행하고 있다. 서비스 개선을 위해 동의를 받는 것들 중 많은 것이 이런 최적화에 활용되고 있는 것이다.

디자인 면에서 웹최적화는 개인적으로도 전부터 무척 관심을 가졌던 분야다. 그런데 그것과 관련된 정보를 얻을 수 없었다. 고작해야 트렌드 서적 같은 곳에서 선거 때, 어떻게 이길 수 있었다는 정도였지, 구체적인 기술은 볼 수 없었다. 그런데, '머신러닝을 활용한 웹 최적화'에는 처음부터 그것을 다룬다. 미국 오바마 대선 당시, 지원자 등록 사이트에 A/B 테스트를 통해 어떤 사진과 버튼의 문구가 최적 조합인지 찾아서 지원자 등록률을 8.26%에서 11.6%까지 올렸다고 한다.
여기서 중요한 것은 오바마 얘기가 아니다. 그것을 찾는 수학적인 과정이다. 이것을 알기 위해, 다양한 수학 지식이 필요하다. 이 책을 읽기 위해서는 적어도 고등학교 이과 수학 정도는 알 필요가 있다. 통계와 함께 벡터, 행렬, 미적분 등이 나오고 그것을 좀 더 발전시킨 수학 내용들이 있기 때문이다. 책에 다루는 수학 수준이 어려운 편은 아니지만, 그렇다고 쉽지도 않다. 각종 공식 유도 과정이 자세히 나와 있으나, 특히 6장에서는 중간중간 여러 고비가 오곤 한다. 그래서 그런지 책에도 부록으로 행렬 연산 기초를 통해 파이썬 프로그래밍 방법도 알려주고, 베이즈 로지스틱 회귀, 톰슨 샘플링에 대해 설명을 추가하고 있다.

'머신러닝을 활용한 웹 최적화' 초반부는 A/B 테스트, 확률분포, 이산 같은 일반 통계와 베이즈 통계, 베이즈 추론으로 높은 클릭률을 찾아내고, 체류시간도 생각하며, 어떤 것이 최적의 것인지 판별하는 방법을 익힌다. 초반에는 2개 중 하나를 대상으로 하고, 3장부터는 다양한 요소들을 적용시 어떻게 모델링하고, 어떻게 평가하는지를 말한다.

사실 통계적 방법은 예상을 하고 있었는데, 4장의 모델을 가정하지 않는 최적화 방법인 메타휴리스틱은 무척 생소한 방법이었다. 여기서는 통계가 아닌 언덕 오르기 알고리즘, 시뮬레이티드 어닐링, 유전 알고리즘을 사용한다. 들어 본 것도 있지만, 그걸 어떻게 활용하는지는 여기서 처음 알게 되었다.
5장에서는 최적 모델을 찾는데, 너무 많은 시간과 경비가 들면 안 된다는 현실적인 문제를 알고리즘으로 해결해보는 과정을 다룬다. 기업에 있어 시간은 진짜 돈과 같다. 그래서 개발 현장 어딜 가나 기간 단축을 가장 마지막에 강조한다. 여기서는 다중 슬롯머신 문제를 통해 도출된 슬롯머신 알고리즘과 ε-greedy, UCB 알고리즘 같은 것을 적용해본다. 여기 나오는 슬롯머신 그림은 책 초반부터 여러 곳에서 각종 설명에 활용된다. 그때그때 다른 부분이 있기에 나중에 비교하며 이해하는데도 도움이 된다.
그리고 책에 있는 각종 코드들은 파이썬을 사용하고 있으며, PyMC3 라이브러리를 사용해서 계산에 활용하고 있다. 초보를 위한 책이 아닌 만큼, 파이썬 문법은 다루지 않고 있고, 바로 코드가 나오고 있고, 특별한 경우 외에는 코드 자체에 대한 설명도 하지 않고 있다. 그러나 코드 길이 자체가 짧고, 간단해서, 이해하는데 전혀 어려움은 없을 것이다.

7장에서는 색상, 컬러에 관한 최적화를 다룬다. 이런 것도 프로그램으로 최적화 가능하다는 게 신기했다. 확률 과정으로 가우스 과정을 사용하는데, 생소하지만, 수학 알고리즘을 이렇게 활용할 수 있다는 것이 흥미롭고 재미있었다. 여기서는 색상 최적화에 응용했지만, 비슷한 연속된 값을 가진 모델에 활용해볼 수 있을 거 같다.

이처럼 '머신러닝을 활용한 웹 최적화'은 최적화된 웹을 위해, 인공지능 알고리즘과 통계를 활용한 다양한 기법과 테스트를 위한 최단 시간과 효율적인 방법, 자동화된 방법을 제시하고 있다. 사실 이런 주제의 책은 상당히 보기 드물기에 인공지능, 웹최적화에 관심 있는 사람뿐만 아니라, 분야는 다를지라도 인터넷 마케팅 관련자라면 이런 정량적 방법도 있다는 것을 알기 위해, 한번은 봐 두는 것이 좋을 것이다.
그리고 이 책의 영문 제목에도 나와 있듯이 introduction 소개 정도의 내용을 담고 있다. 웹 최적화에 대한 전반적인 소개인 것이다. 그러나 보면 알겠지만, 단순 소개 정도의 책은 아니다. 방대한 수학 지식을 담고 있어, 사람에 따라서는 난이도가 있는 책이다. 완벽한 이해를 위해, 저자가 제시한 참고문헌도 볼 수만 있다면, 봐야 할 거 같다.
분명 여러 가지로 공부하기 힘든 면이 있겠지만, 인공지능 시대에 걸맞은 기술력을 쌓고, 남보다 앞선 실력을 가진 프로그래머로 성장하고 싶다면, 이런 고급 주제에 대한 공부도 필수라 생각한다. 이 바닥에서 프로그램 언어 아는 정도로 밥 벌어먹기는 이젠 힘들다고 본다. 인공지능이든, VR이든, 자신만의 독보적 프로그램 기술이 필요하다. 그런 면에서 '머신러닝을 활용한 웹 최적화'는 좋은 길을 제시할 것이다.
오래된 영화들이지만, 유주열 서스펙트나 식스센스와 같은 반전 영화를 기억하시는분들이 많을 거라 생각합니다. 예상에서 벗어나는 반전이라는 연출이 그만큼 인상적인 경험을 주기 때문이라생각하는데요, 이 책을 읽으면서 마치 반전영화를 보는 듯한 경험을 하였습니다.
책제목의 '최적화' 단어만 보고 성능과 관련된 내용일 거라생각하고 봤습니다만, 책의 서론에서부터 그러한 내용은 다루지 않는다고 못박으며 개발자와 사용자 사이에서일어나는 가설 검증 사이클을 통한 웹 서비스의 목표 최대화 및 최소화 고정을 웹 최적화라고 정의합니다. 그리고베이즈 통계, 마르코프 체인같은 확률 통계 단어들을 언급하며 선형대수,미적분 등의 수학적 지식은 알고 있는 것을 전제로 한다며 겁을 줍니다. 이 시점에서 책을잘 못 골랐구나 후회하며 책을 넘길 의욕을 잃게 됩니다만, 포기하지 않고 페이지를 넘기면 너무나도 친절하고상세하게 기초적인 내용부터 차근차근 설명하며 진행되는 내용에 흥미를 가지며 빠져들게 됩니다. 2008년미 대선에서 오바마의 지원자 등록 사이트 사례를 통해 독자의 흥미를 불러 일으키며 A/B 테스트를 기초적확률 개념부터 상세히 설명하는 과정을 통해 서론에서 느꼈던 불안감과 후회가 호기심으로 바뀌는 데에는 오랜 시간이 걸리지 않았습니다.
책의저자도 통계 관련 지식이 없던 상황에서 이러한 학문에 입문하게 되었던 경험을 살려 저술한 통계학과 머신러닝에 입문하기 위한 책이라 서론에서 언급하고있는 만큼, 어렵지 않게 진입 장벽을 낮추기 위해 많은 노력을 기울인 서적이라 느꼈습니다. 책의 제목이나 목차만 보고 저처럼 너무 무서워(?) 하지 마시고이러한 주제에 관심 있는 분이라면 꼭 일독을 권하고 싶은 책입니다.
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
하루가 멀지 않게 IT 기술의 변화는 놀랍게 빠릅니다.
그중 제일 많이 변화는 기술은 '최적화' 쪽이지 않을까 생각이 듭니다.
포털 사이트들의 검색 내용, 광고 위치 심지어 폰트 크기까지 최적화를 하지 않는 곳이 없습니다.
최적화를 하는 가장 큰 이유는 사용자들의 편의 제공과 기획의 의도 대로 가는지 보는 것입니다.
최근 핫한 기술인 머신러닝 분야의 웹 최적화에 관련된 내용이 나왔습니다.

바로 '머신러닝을 활용한 웹 최적화'란 책인데요.
저자는 개발자 출신의 UX 엔지니어로 구글러입니다.
저자가 도교 대학에서 재학 때 웹사이트 최적화 연구를 했습니다.
그 이후 실리콘밸리 연구 여행 및 박사 과정을 통해서 깨달은 내용을 정리 한 책입니다.
가장 설명해드리고 싶은 부분은 A/B 테스트 부분인데요.
A/B 테스트는 집단을 테스트해서 어떤 조건이 성과가 좋은지 측정하는 테스트입니다.
실험 예제로 버락 오바마 공식 웹사이트의 A/B테스트를 같이 알아보겠습니다.
여러 조건의 버튼을 테스트해서 가장 등록률이 향상되는 조합을 찾았습니다.
여기서 등록률이 가장 높았던 조합이 궁금하지 않으신가요?
오바마가 가족과 함께 찍은 이미지와 LEARN MORE라고 적힌 조합이었습니다.
사례를 통해 여러 가지 조건의 가설을 세우고 접근하는 것이 중요함을 보여줍니다.

Ps.
코로나 19 이후로 IT 업계 변화의 바람은 크게 불고 있습니다.
이 책은 웹 최적화에 관심 있는 분들인 웹 개발자, 마케터들도 알고리즘에 쉽게 접근 할 수 있도록 쓴 책인데요.
기초 통계가 부족하더라도 파이썬에 대한 기초적인 지식만 있다면 책의 내용이 쉽게 정리가 돼 있어서 술술 읽히리라 생각이 듭니다.

한빛 미디어에서 '머신러닝을 위한 웹최적화'라는 책을 리뷰어 활동으로 지원받아 읽게 되었다.
실제 웹 서비스 디자인에서 A/B 테스트를 어떻게 구성해야하고, 어떻게 발전시켜나가야하는지 궁금해서 신청하게 된 책이다.
책은 첫장에서부터 구성을 친절하게 알려주며 이야기를 시작한다.
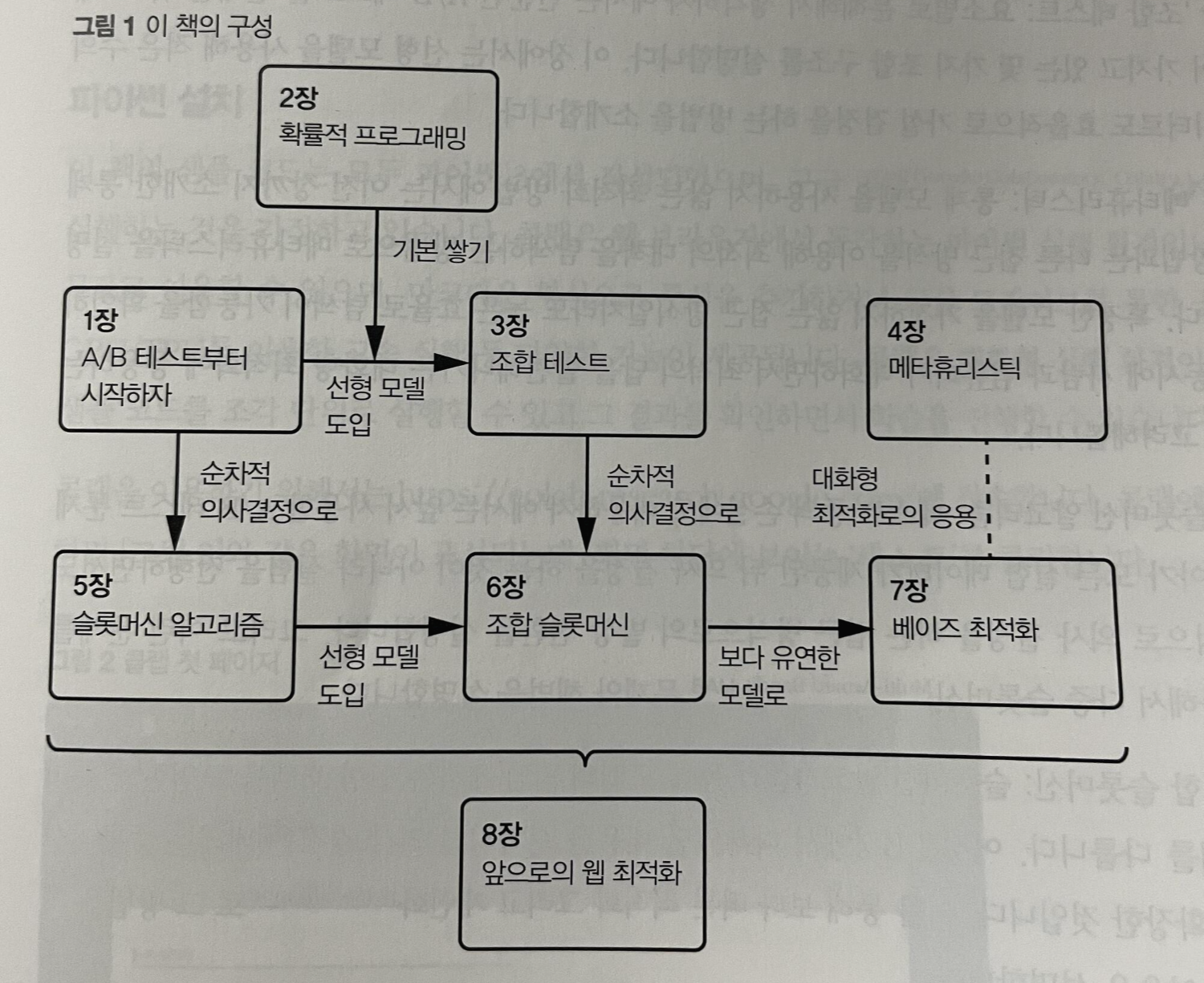
1장과 2장은 주로 기초 내용과 A/B 테스트가 필요한 상황에 대한 내용을 다루며, 그외의 장들에서는 화살표가 이어지는 대로의 니즈에 맞게 설명들과 예시들이 이어진다. 책 내용 자체도 어려운 이론들보다는 실제 예시(디자인 시안)를 토대로 진행되기 때문에 읽음에 있어서도 큰 어려움은 없었다.
사실 기존에 머신러닝만 공부했어서 웹 관련 내용들을 잘 이해할 수 있을까 걱정하는 마음으로 읽었는데, 생각외로 고전 인공지능 알고리즘(힐 클라이밍, 유전 알고리즘, 슬롯머신 등등..)이 나와서 반갑게 읽혔다. 하지만 이런 점들은 인공지능, 머신러닝을 잘 모르는 분들에게는 어려움이 될 수도 있지 않을까 하는 생각이 들었지만, 책에서 또 많은 예제와 코드들로 설명을 해주어서 파이썬 코드를 읽음에 어려움이 없는 분들이라면 쉽게 이해하실 수 있을거라는 생각이 들었다.
책 내용 자체에 대해서는 정말 만족했던 책이다. 특히 A/B 테스트가 무엇인지에 대해 어렴풋이나마 알고 있던 분들 혹은 더 깊게 알고 싶은 분들, 머신러닝을 적용하여 A/B 테스트를 구체화하고 발전시켜나가고 싶은 분들에게 추천하고 싶은 책이다.


첫장부터 베이즈 통계, 확률 이런 이야기가 나온다. 비전공자로서 어렵지 않을까 약간 고민되었다.



통계 수식이 나올 것 같았는데, 진짜 이런 수식이 중간 중간에 마구마구 나온다. 이해하면 좋겠지만, 전 읽지 않고 통과했어요. 읽어도 모르니까요. 몰라도 책 전체 내용을 이해하는데는 별 무리가 없을 것 같다. 초반 수식은 그래도 좀 이해가 갔는데, 중반부터는 정말 어려웠어요. 통계 전공하신 분들에게 도움이 되실 것 같아요.


네, 소프트맥스 알고리즘, 딥러닝때 배운 알고리즘이네요. 이렇게 딥러닝, 강화학습 좀 공부하셨다면, 이것을 통해 A/B 테스트 할 때 고려할 상황들이 무엇인지 많은 도움이 됩니다.

책 중반이후, 강화학습 이야기가 많이 나옵니다. 이 이미지만 봐도 느낌이 딱 드시죠. 그런데, 용어들이 통계학 용어라서 약간 낮설어요.
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
이 책도 제목만 보고 오해했다.
이 전에 읽었던 "LEAN AI"의 제목을 보고 AI에 방점이 찍힌 책이라고 생각했던 것처럼.
오히려 이 책의 내용이 'LEAN AI'라는 책의 제목을 보고 예상했던 책의 내용이었다.
'웹 최적화'라는 단어를 저자의 분류에 따르면 '웹 퍼포먼스 최적화'라고 생각하는 오해를 한 것이다.
여기서 '웹 최적화'는 A/B TEST 형태의 테스트를 통해 좀 더 사용자 친화(?), 사업 목적에 맞게 웹페이지를 구성하는 것을 말한다.
책에서는 A/B TEST, 베이즈 추론, 마르코프 연쇄 몬테카를로 알고리즘, 메타휴리스틱등 다양한 내용을 설명하고 있다. 하나 하나 다 어렵지만, 다행히도 해당 내용이 파이선 소스를 예제로 제공된다.
단, 파이선의 라이브러리는 변화가 심해서 저자의 환경과 동일하지 않으면 오류가 나기 싶다. colab을 사용하는게 그나마 따라하기 편한 것 같다.
또한 DE, DA한테는 당연할지 모르겠지만, 왜 변수가 많은 유연한 모델이 있으면, 그 전에 있단 단순한 모델은 교육용이가 실제로는 사용되지 않는 것인지 같은 질문에 대한 답변같은 것들도 책에 담겨져 있어서 좋았던 것 같습니다.
'LEAN AI'가 추상적인 이야기 였다면, '머신러닝을 활용한 웹 최적화'는 좀 더 구체적이고 지엽적인 이야기라 실무자 입장에서는 좀 더 좋기는 했지만, 어느 정도 기반 지식이 없다면 난이도는 있는 책이라고 생각한다.
특히 p.232에서 부터 시작하는 '베이즈 정리에 적용하기'는 이해 불가. ㅠㅠ

이 책의 제목을 처음 봤을 때 단순히 A/B 테스트로 웹 사이트를 최적화하는 방법에 대한 것으로만
생각했습니다.
그러나 이 책은 "베이즈 통계학"을 바탕으로 하고 있습니다.
서문에서 저자는
'사용자의 행동에서 얻은 데이터로 부터 조금이라도 도움이 되는 결과를 얻기 위한 강력한 문기가 통계학과 머신러닝 관련 지식'
이라고 말하고 있습니다. 즉,
'개발자와 사용자 사이에서 일어나는 가설 검증 사이클을 통해 웹 서비스가 가진 모종의 목표를 최대화 혹은 최소화 하는 것'을 '웹 최적화'라고 말하고 있습니다.
그러나, 이런 가설 검증 사이틀을 통한 최적화는 웹에만 국한된 것이 아니라 개발자가 개발하는 모든 프로그램에 적용되는 것이 아닌가 싶습니다.
이 책은 처음에 확률적 프로그래밍에 대해 설명하는데 베이즈 이론에 대한 기본적인 설명을 소스코드와 함께 설명을 하고 있습니다. 막연하게만 알던 내용을 실제 사례를 보면서 읽게 되니 머리속에 어느정도 이 책이 추구하는 내용이 그려집니다.
그리고 요즘도 많이 사용하는 A/B 테스트를 시작으로 조합 슬롯 머신과 메타휴리스틱을 통해 베이즈 최적화를 설명하고 있습니다.
사용자의 반응을 보면서 '믿음(belief)'의 정도를 높여가면서 결과를 도출하는 방법은
변화주기가 빠른 오늘날 환경에 적절한 방법이라 생각합니다.
사용자의 실질적인 반응없이 상상만으로 시스템을 구현하는 것(개발자 자신이든 아니면 관리자들에 의한 것이든)은 상당히 많은 리스크가 있습니다. 아마 대부분의 개발자들이나 기획자들이 어떤 서비스 방법을 설계하고 개발했을 때 변화된 사용자 요구사항에 맞지 않아, 처음부터 다시 개발하는 경우가
많았을 겁니다.
물론 이 베이즈 최적화도 만능은 아니겠지만, 어느정도 이런 상황에서 도움이 되는 방법이 아닐까 생각합니다.
이 책은 저에게는 '진흙속의 진주' 처럼 우연히 찾은 좋은 책이라 생각합니다.
"이 글은 한빛미디어 '나는 리뷰어다.' 서평단 자격으로 작성된 글입니다."
A/B 테스트를 중심으로 통계 및 머신러닝을 활용하여 웹사이트 최적화 기법을 다루는 책이다. 연구 성과를 일목요연하게 잘 정리하고 있고, 실전에 적용하는데 필요한 고민과 해법이 같이 담겨 있다.
읽다보면 매우 간단한 예제 2개만으로 통계가 실전에서 어떻게 활용되는지 생생하게 접할 수 있다. 통계, 베이즈 추론 등에 숨겨진 개념을 실용적으로 끌어내는 방법을 비롯해 해당 분야의 연구 성과가 잘 정리되어 있어 실전에 적용할 만한 연결고리를 찾을 수 있다는 점도 장점이다.
책은 크게 2개의 예제를 중심으로 살이 붙어나가는 방식이기에 이를 중심으로 책의 내용과 배운점 및 장점을 요약해 본다.
예제1 : 앨리스와 밥의 A/B 테스트
아래 그림은 앨리스와 밥이 상품 소개 페이지의 자료 요청 버튼의 클릭율을 높이기 위하여, 두 가지 디자인 A, B안을 준비한 후 노출 횟수 및 클릭 횟수를 측정한 결과이다. 클릭률이 우연히 동일하게 나왔지만 각 횟수가 다르기에 B안을 선택해야 한다고 결론을 내릴 수 있을까?
저자는 이 예제를 활용하여 웹사이트 최적화에 필요한 기본 지식을 정리한다. 확률 변수, 베르누이 시행, 확률 분포, 확률 분포의 파라미터, 정규화, 확률의 덧셈정리를 활용한 주변화(marginalization), 베이즈 업데이트를 활용한 사후 분포 시각화 등이 그것이다.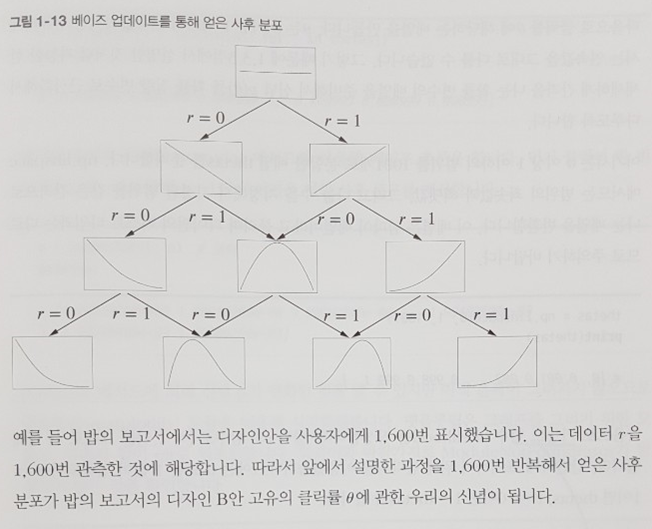
그 중 사후 분포를 정량적으로 평가하기 위한 방법 2가지가 소개되는데 이 부분부터 웹사이트 최적화에 유용한 기법들이 본격적으로 소개되기 시작한다. 하나는 시행 반복을 통한 통계 모델링을 활용하여 분포를 추정하는 방법이고, 다른 하나는 사후 분포에 나타난 베타 분포를 활용한 방식인데 후자가 중요한 방식이다.
먼저 후자 방식의 기초 통계량을 활용하는 방법이 소개되고 그 중 클릭율 사후 분포의 HDI - 확률 변수의 값이 높은 확률로 나타나는 구간 - 를 구하여 확률 질량이 큰 순서대로 상윗값을 반환하는 hmv 메서드를 만들어 “디자인 B안의 클릭율은 5%보다 높다.”와 같은 가설을 만든다. 그 과정을 도식화하면 아래 그림과 같다.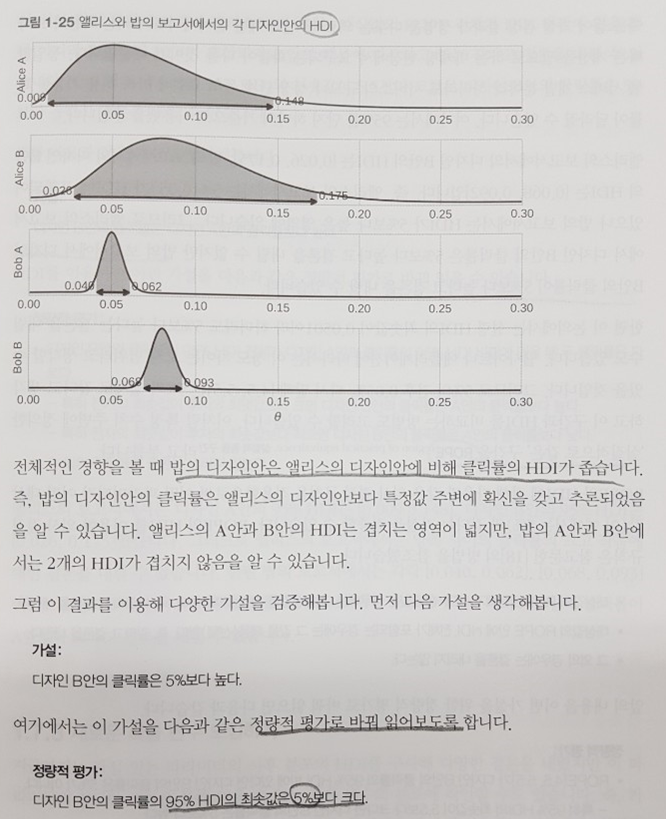
이어서 A안의 클릭율과 B안의 클릭율의 차이인 파생 변수를 생성해보는 등 추가 시도를 거치는데 큰 확률이라는 값이 95%면 충분할 지, ROPE 폭과 같이 검증하고자 하는 가설을 정량적 평가로 변환하는 과정 등 실무에서 공유되어야 할 도메인 측면에 대한 고민도 담겨 있어 유용했다.
여기까지가 통계와 웹최적화의 기본이었다면 2장 부터는 MCMC(마르코프 연쇄 몬테카를로 알고리즘)을 활용한다. 초기값은 최적의 파라미터 주위에 근접하도록 상태를 전이시키지만 이런 부분이 영향을 미치지 않도록 어느 정도 탐색이 진행된 뒤의 샘플을 얻는다. PyMC3 모듈을 활용하여 MCMC를 시각화하여 볼 수 있어 이해에 도움이 된다.
특히 개인적으로는 가능도 함수의 분포인 베르누리 분포, 카테고리컬 분포, 이항 분포, 다항 분포와 신념(믿음)의 분포인 베타 분포, 디리클레 분포의 총체적인 관계를 정리해 볼 수 있어 만족스러웠다. 그동안 통계학에서 다루는 분포 대부분의 개념은 잘 숙지하고 있었지만 분포 간의 변화와 관계가 늘 궁금했는데 앨리스와 밥의 문제로 변수를 최소화 한 접근법 덕분에 비교적 명쾌하게 이해할 수 있었다.
여기서 끝났어도 충분히 만족스러웠는데 하나 더 저자에게 고마움을 느낀 부분이 있다. 2장의 마무리 단계에서 NHST(귀무가설 유의성 검증)과 베이즈 추론 간 통계적 가설 검증을 비교해본다. 통계학 비전공자라 볼 때 마다 헷갈린 부분인데 이 책을 통해 감을 잡을 수 있었다.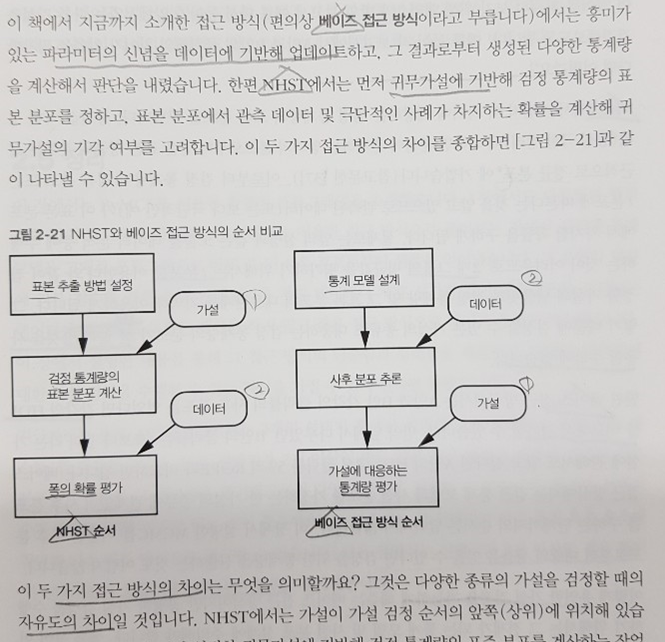
두 검증의 차이는 일단 기본적으로 자유도에 차이가 있다. NHST는 잘 알려진 분포만 활용한다는 한계가 있지만 검정 통계량을 신뢰할만하다. 반면 베이즈 접근 방식의 경우 앞서 예제와 같이 HDI를 비교 평가 할 수 있어 유연한 가설 검증이 가능했다. 하지만 적절한 사전 분포를 설계해야 한다는 제약 조건이 따르며 적응 데이터 분석 및 과적합 문제를 안고 있다는 사실로 정리해 볼 수 있었다.
사실 딥러닝을 먼저 시작한 나로써는 데이터가 많은 요즘 같은 시대에 검정, 추정을 실전에서 어떻게 활용하는지 늘 궁금했었고, 나아가 베이즈 추론과 사후 분포의 위력을 체감하기 어려웠는데 앨리스와 밥의 A/B 테스트와 같이 심플한 예제 덕분에 통계에 숨은 개념을 현실로 끌어내는데 큰 도움이 되었다. 이어질 두 번째 예제는 보다 어렵지만 나 같은 통계 하수는 1 ~ 2장만으로도 충분히 만족스러운 책이라고 평하고 싶다.
예제2 : 조합형 4가지 디지안 시안 테스트
제목은 어려워 보여도 이 역시 너무 간단한 예제이다. 아래 그림과 같이 시안 A,B,C,D 중 어떤 시안이 가장 뛰어날지 판단하는 문제이다. 위 예제1과 다른 점이 있다면 A,B는 그림이 같고, C,D는 버튼 문구가 다르다. 즉, 그림과 문구 간 조합이라는 요소가 존재하는 예제이다. 예제1은 개념을 익히기에는 좋은 예제이지만 실전에서 바로 활용하기는 어렵기에 예제2릍 통해 실전에 한 걸음 다가갈 수 있는 셈이다.
이 예제에서는 무엇보다 통계 모델링을 구체적으로 진행하는 방법이 소개되어 있어 유익했다. 예제1에서 배웠던 분포를 활용하여 이미지 변경에 따른 클릭율, 버튼 변경에 따른 클릭율, 베이스라인 클릭율 등 새로운 파생 변수를 도입한 후 로짓 함수 및 정규 분포를 활용하여 아래와 같이 최종 클릭율을 예측하는 모델을 만든다.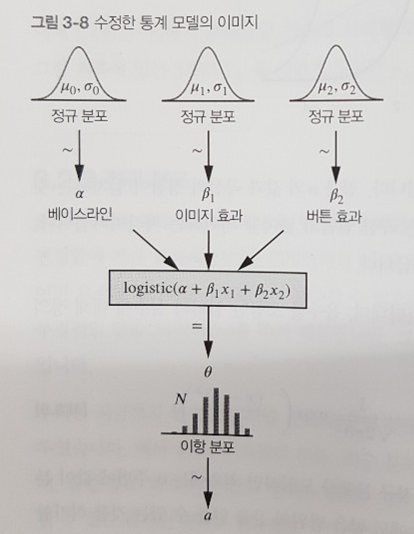
이어서 요소의 조합에 의해 발생하는 교호 작용을 파악하고 모델에 교호 작용항을 추가한다. 이는 통계 기본에 해당하는 다중 공선성의 문제인데 교호작용을 어디까지 고려해야 할 지 생각해 볼 수 있는 좋은 기회였다. 4장에서는 해결책 중의 하나로 메타휴리스틱을 접목해본다.
오른쪽 그림과 같이 접근하면 교호작용을 고려하거나 최적 변수 선택의 고만이 필요없다. A*알고리즘과 같이 목적지와 현 위치 사이의 추정거리를 휴리스틱으로 도입하는 셈이다. 이를 책에서는 언덕 오르기 알고리즘(Hill Climbing)이라고 정리하고 있다.
생긴 것이 딥러닝의 손실함수 경사하강법 문제와 비슷해 보인다 싶었는데 역시나 여기에서도 국소 최적문제가 등장했다. 이를 해결하고자 마치 SGD처럼 확률적 언덕 오르기 알고리즘, 온도 파라미터를 도입한 시뮬레이티드 어닐링, 교차율을 도입한 유전 알고리즘 등이 소개되는데 하나 하나 괜찮은 아이디어였다. 딥러닝이 통계와 얼마나 밀접한지 실감할 수 있었다.
5장에서는 보다 실전에서 고민할 만한 사항이 등장한다. 테스트 중에 발생하는 손실, 기간 등에 대한 문제도 다룬다. 즉, 강화학습에서 흔히 볼 수 있는 다중 슬롯머신 탐색과 활용 딜레마가 웹페이지 최적화에도 등장하는 문제임을 알 수 있다. 이를 해결하기 위한 방법으로 Epsilon-Greedy, 시뮬레이티드 어닐링 Epsilon-Greedy, Softmax, 톰슨 샘플링, UCB 등의 아이디어가 소개된다.
5장이 다소 연구적인 느낌의 정리였다면 6장은 5장에서 배운 연구 성과를 실전에 접목해보는 형태를 띈다. 즉, 눈 앞의 슬롯머신이 변하듯 개인화 구현의 문제로 넘어간다. MCMC를 베이즈 선형회귀에 접목하는 방법에서 연구 성과를 실전에 적용하는 방법론을 배울 수 있었다. 5장에서 배운 UCB를 응용해서 LinUCB를 구현해내는 과정은 머리속에 떠오른 아이디어를 어떻게 기존 연구에 연결할 수 있는지 그 경계선을 느끼게 해줬다.
그 외에도 7장에서 배운 가우스 과정을 톰슨 샘플링에 적용한 GP-TS 알고리즘은 UCB에 아이디어를 살을 붙여 가는 방법을 알게 해줬다. 덕분에 읽으며 개인적으로 괜찮은 아이디어가 떠올랐는데 이를 접목해보고 논문을 써봐야겠다는 생각이 들었다. 이처럼 생소한 분야에 연구적 커넥팅을 가능하게 해준 다는 점은 이 책의 큰 장점 중 하나이다.
8장에는 웹 최적화 분야에 앞으로 필요한 기술들이 소개되는데 오토인코더가 등장해서 신선했다. 다양한 AI 분야가 존재하지만 상호 영역을 잘 알아두고 조합한다면 어떤 분야에서든 멋진 아이디어가 파생될 수 있겠다는 생각이 들었다.
적어도 내 수준에서는 이 책에서 너무도 많은 것을 배울 수 있었다. 위에서 언급했듯 통계가 실전에 어떻게 적용되는지 너무 심플한 예제로 통계학에 숨어있는 지식을 생생하게 느낄 수 있게 해준 점, 저자 특유의 웹 최적화 분야 연구 성과 전달력 덕분에 아이디어를 연구 혹은 실전에 적용하는 연결고리를 얻게 해준 점 등 큰 도움을 받았다.
리뷰를 통해 저자, 역자, 편집자 분들께 진심으로 감사의 말씀을 전하고 싶다. 웹최적화 뿐만 아니라 통계나 머신러닝에 관심있는 독자에게 꼭 추천하고 싶은 책이다.
한빛미디어 “나는 리뷰어다” 활동을 위해서 책을 제공받아 작성된 서평입니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
머신러닝에 `확률과 통계`는 꼭 필요한 수학 중 하나라고 생각합니다. 그렇기에 머신러닝 분야를 좀 더 자세하게 공부하기 위해서 대학에서도 `확률과 통계` 수업을 듣기도 했고 개인적으로 책을 보며 따로 공부하기도 했었습니다. 그렇기에 이 책을 읽기에는 충분히 읽을 수 있다고 생각했습니다.
또한 이 책의 부제에는 `A/B 테스트`라는 키워드가 있습니다. 최근에 저는 웹 백엔드와 데이터 분석 쪽을 공부하고 있기에 A/B 테스트에 대해 더 세부적으로 공부해보고 싶었습니다. 또한, 이 책은 제가 머신러닝을 배우면서 공부했던 내용들을 웹 최적화에 도입해볼 수 있다는 점이 저에게 너무 매력적으로 다가왔기에 꼭 읽어보고 싶었습니다.
책 리뷰
웹 최적화
저는 머신러닝을 공부하면서 다양한 기초 지식들을 공부했었습니다. 이 책은 기초적인 확률과 통계 지식, 최적화 이론 등의 내용들을 어디에 사용할 수 있는지 알려줍니다. 지금까지 온갖 책, 강의 등에서 공부했던 내용들을 응용하는 책입니다. 이론적인 내용보다는 `웹 최적화라는 것을 어떻게 머신러닝으로 적용했을까`에 더 가깝습니다. A/B 테스트를 예시로 들어가면서 베이즈 정리를 활용해 A안과 B안 중 어느 것이 더 좋은가를 알려주는 등의 웹 최적화에 관한 예시들을 제시합니다. 응용에만 너무 가깝다고 해서 이론적인 내용들이 없는 것은 전혀 아닙니다. 필수적인 알고리즘, 확률과 통계 지식들은 적절하게 잘 설명되어 있습니다. 개인적으로 Chapter 7 베이즈 최적화가 가장 어려우면서 흥미 있게 봤던 부분이었습니다.
부록
이 책의 끝을 보면 부록이 있습니다. 부록에서는 책에서 설명했던 계산들을 이해하기 위해 꼭 필요한 연산들이 설명되어 있습니다. 혹시나 책을 읽으시면서 어려운 점이 있으시다면 부록을 참고하시면 될 것 같습니다. 책을 읽기 위해 최소한의 정보가 있기 때문에 만약 서점에서 이 책을 사시는 분들이 있으시다면 부록을 먼저 보시고 이 정도는 이해하실 수 있다고 판단이 된다면 구매하시는 걸 추천드립니다.
코드
코드는 주피터 노트북으로 주어집니다. 이 책에서는 모든 샘플 코드는 구글 콜랩 상에서 실행하는 것을 가정하고 있다고 되어 있습니다. 이런 부분은 공부하는 입장에서 너무 편하고 좋았지만 가장 아쉬웠던 점은 예제 코드가 딱 한 파일으로 되어 있기 때문에 보기 어려웠습니다. 각 Chapter 별로 나뉘어져 있었으면 좀 더 실행하기 편리했을 것 같았는데 하나하나 다 실습해보는 독자로써 너무 아쉬웠습니다.
대상 독자
- 통계학 또는 머신러닝에 입문하고자 하는 웹 엔지니어
- 웹 마케팅 관련 담당자, 웹 마케터
- 머신러닝 응용, 특히 사람과의 상호 작용에 대한 응용에 흥미가 있는 분
제가 추천하지 않아도 이 책에 대상 독자가 위처럼 기술되어 있습니다. 근데 솔직히 이 책이 쉬운 책이 아니라 최소 통계적인 지식이 어느정도 있으신 분이 읽으셨으면 좋겠습니다. 슬롯머신 알고리즘, 베이즈 정리, 회귀 등 꽤 어려운 내용들이 많기에 머신러닝도 먼저 공부해본 분들에게 추천드립니다. 책 제목부터 머신러닝을 `활용한` 웹 최적화입니다. 꼭 사전 지식이 있으신 분들이 읽으시길 바라겠습니다.
한빛미디어에서 제공받는 책으로 해당 리뷰를 작성하였습니다.

머신러닝, 딥러닝, 선형대수 그리고 통계처럼 AI 분야에서 직접적으로 사용되는 기술이나 이론은 어렵지 않지만, 막막하다. 개별적인 이론이나 기술을 학습하는 할 때, 좋은 교재도 많고 Coursera 등에 강의도 다양하기 때문에 생각보다 어렵지 않다(쉽다는 뜻은 아니다). 하지만 어느순간 막막함이 찾아온다. 당연하게도 학습자의 대부분이 풀고자 하는 문제는 iris처럼 단순하지 않고, MNIST처럼 쉽게 진행되지 않기 때문이다. 하지만 이런 사소한 질문보다 더 큰 의문이 앞을 가로막을 때가 있다.
“도대체 이 기술을 어디에 써야 하는가?”이다.
사례를 찾아보고, 여기저기 풀지 못한 문제를 찾아가보지만 코끼리 다리를 만지는 것도 쉽지 않다. 대부분의 교재나 강의가 ‘모델’과 ‘해석’ 기술을 가르치고 있기 때문이며, 실제 응용할 수 있는 사례를 찾기 위해선 적당한 분야(domain or field)가 있어야 되는데 어떤 분야에 내가 배운 AI 기술을 접목할 수 있을지 막막하다면, 이 교재로 시작해보자.
일단 이 교재는 “해보고(do), 배워보는(learn)” 형식의 책이다. 이런 종류의 책이 가지는 단점은 해보는 것이 중구난방(衆口難防)인 경우가 많고, 그게 아니라면 배우는 내용의 깊이가 전혀 없다는 점이다. 이 책은 이런 단점을 모두 피해간다. 이 책은 일관된 하나의 분야를 지향하고, 생각보다 깊이가 깊다. 그것도 많이 깊다. 그래서 난이도가 조금 올라가는 측면이 있지만 잘 작성된 코드를 제공하기 때문에 용기만 있다면 배우는데 큰 무리는 없다.
이 책의 제일 큰 혼돈은 제목인데, 왜냐하면 최적화라는 단어를 개발자가 접했을 때와 기획/마켓터가 받아들일 때 전혀 다른 상상을 할 것으로 예상되기 때문이다. 개발자는 이책을 AI 기술을 사용해서 웹 최적화를 진행할 듯 보이고, 기획/마켓터는 통계를 기반으로 UX를 개선할 것으로 받아들일 수 있다. 이 책은 그 모든 것을 다룬다. 기술적으로 웹을 최적화 하는 방법과 통계적으로 UX를 개선하는 방법을 모두 다룬다.
그래서 이 책은 개발자,마켓터, 기획자와 함꼐 보면 좋은 내용이 많다. 스타트업이나 팀단위 업무를 진행한다면 사내 스터디, 세미나, 기타 등등의 방법을 동원해서 관심있는 분야을 함께 읽어보길 권한다. 현재의 서비스를 개선해 볼 수 있다는 방법을 직접적으로 제공하기 때문이다.

머신러닝, 딥러닝, 선형대수 그리고 통계를 실제 서비스 적용하는 사례가 흔하지 않다.A/B Testing를 시작으로 서비스에 적용본다면 현재 서비스에 대한 다양한 관점을 가져볼 수 있을 것이다. 개인적으로 가장 흥미롭게 봤던 예제는 샘플링을 사용해서 최적화된 색상을 찾는 방법이었다. 읽으면서 이 정도 수준의 예제는 당장 적용가능할 것으로 생각해서 친구들과 가벼운 토이 프로젝트를 진행하기로 했다.
파이썬으로 간단한 코드를 수행할 수 있고, 고등학교 수준의 통계적인 지식이 있다면 이 책의 예제를 시작으로 기술적인 도전을 시작해보자!

필자는 이 책을 통해서 Toy 프로젝트를 진행하고 있다. Toy 프로젝트 진행하면서 도움이 된 다른 서적과 자료는 아래와 같다.


이번 읽은 책은 "머신러닝을 활용한 웹 최적화"입니다.
대상독자
머신러닝을 배우긴 했는데 어디에 사용을 해야 할까? 그리고 어떻게 적용을 해야 할까?
처음 AI 분야를 공부 하게 되면 하게 되는 생각입니다.
저는 대상 독자를 2개 분야를 꼽아봤습니다.
1. 개발자
만약 본인이 웹개발을 하고 있다면 고객 유입에 관련 된 일은 기획에만 맡기면 된다는 생각은 버리는게 좋을듯
합니다. 머신러닝을 공부 했다면 좋은 연습 예제가 되기 때문에 적극활용 해보시기 바랍니다.
2. 기획자
우리 웹사이트에 유입 되는 고객은 내가 가장 잘 알고 있다고 착각 하기 쉬운 포지션이라 생각합니다. 실제 고객이 원하는것은 기획자가 예상 하고 있는 그것이 아닐수 있습니다.
그 외 관리자급
테스트는 쓸데없이 시간을 들여서 하는것이 아닙니다. 테스트를 기획 하고 구현 하는것이 얼마나 어렵고 시간이 많이 걸리는 작업인지 알면 그렇게 쉽게 말 못하실거에요.
난이도
수포자인 저의 입장에서 읽는동안 느낀점은 "어렵다....."였습니다.
중간중간 읽을 방법도 모를 수학식이 나옵니다.
하지만 그 수학식을 프로그램으로 표현을 하기 때문에 수학식을 완벽하게 몰라도 프로그램만 이해 하려고 노력 해도 무리 없이 끝까지 읽을 수 있습니다.
내용

AB 테스트라는것은 어려운것이 아닙니다. A형과 B형을 만들고 고객 또는 테스터가 사용하게 하여 어떤것이 더 나은가 테스트 하고 분석을 하는것입니다. 1~2개를 테스트 하겠다 하면 별로 힘든 작업은 없습니다. 단지 시간과 노력이 필요할뿐..
이 책의 시작은 AB 테스트로부터 시작합니다.
여러가지의 디자인안을 만들고 테스트와 분석을 하고 또 다시 추론을 하여 테스트 하고 분석을 하고 이런 반복을 프로그램의 힘을 빌려서 하는 방법을 독자에게 알려주고 있습니다.
우리는 그 결과를 보고 판단을 하면 되는것입니다.
그 외...


머신러닝 공부를 하면 수학은 선택이 아닌 필수가 되고 있습니다.
이 책에서는 후반부에 부록으로 필요한 수학을 첨부 하여 부담을 조금은 덜어주고 있습니다.
물론 책을 읽어 나가기 위한 최소한의 정보이므로 계속 공부해야 하겠죠?

머신러닝을 활용한 웹 최적화

머신러닝이나 통계 이론만을 익히다 보면 실제 내 서비스에 어떻게 적용해야 할지 난감해진다. 책도 읽고 여러 모델도 돌려봤지만 실제 서비스에 적용해 보는 건 또 다른 얘기가 된다. 그리고 타이타닉 예제를 돌려보더라도 다른 분류 예제에 적용해 볼 수 있다는 건 알지만 실제 내 예제에 적용하기까지의 과정이 쉽지 않다. 이 책을 선택해서 읽게 된 계기도 구체적인 상황에 머신러닝이나 통계적인 이론을 적용하기 때문이다. 그래서 머신러닝이나 통계적 이론이 없으면 책 내용이 어렵게 느껴질 수도 있다.
머신러닝과 통계적인 기본적인 내용을 학습한 사람이 웹 혹은 모바일 서비스 등을 개발하며 응응 사례를 참고해 보기에 적당한 책이다. 이 책은 머신러닝이나 통계의 전반적인 내용에 대한 학습보다는 웹 최적화라는 주제를 통해 실제 서비스 개선을 위해 해볼 수 있는 여러 사례를 알려준다.
Learning By Doing 방식으로 쓰여진 책을 좋아하는데 이 책이 그런 책 중 하나다. 얼마전에 리뷰했던 비즈니스 머신러닝도 비슷한 종류의 책이라 볼 수 있을거 같다.
책 제목만 봤을 때는 웹 최적화라고 되어 있어서 웹 트래픽을 최적화 한다는 걸까라는 생각이 들었다. 그런데 막상 목차를 보고나니 웹 개발자 혹은 마케터, 기획자가 함께 보면 좋은 내용일거라는 생각이 든다. 물론 난이도가 있기 때문에 소스코드를 이해하고 적용해 보는 건 다른 얘기지만 다양한 통계적 기법을 통해 서비스를 개선해 볼 수 있다는 방법을 알아볼 수 있다는 점이 장점이다.



통계적 검정이나 머신러닝을 적용한다면 무언가 개선을 하고 또 다른 실험 계획을 세우고 개선하는 과정의 반복이 될것 같다. 서비스 개선을 위해 머신러닝을 적용할 수 있는 예제를 통해 개발자는 구체적인 적용 사례를 알아볼 수 있고 마케터나 기획자는 어떤 시도를 해볼 수 있을지에 대한 아이디어를 얻을 수 있는 책일 것 같다.
머신러닝이나 딥러닝을 서비스 개선에 활용하는 사례에 관심이 많은데 이 책은 A/B Testing, 슬롯머신, 베이즈 최적화 등을 활용하여 어려운 통계적 개념을 서비스에 적용하는 사례를 알려준다.

행렬 연산의 기초가 책의 가장 뒷 부분에 나오는데 이런 배치 구성도 좋다고 생각한다. 아마 처음부터 행렬 연산의 기초, 파이썬 기초가 나왔더라면 지루했을 것이고 또 이 책을 구매해서 보는 사람은 어느정도 파이썬이나 머신러닝, 통계에 대한 기초 지식이 있는 사람들이지 않을까 싶은 생각이 든다.
그래서 파이썬으로 머신러닝 예제 코드를 돌려봤고 통계적인 지식도 어느정도 있는데 웹 서비스를 통해 사용자 행동 개선에 관심있는 사람들이 보면 적합한 책이지 않을까 싶다.
이 리뷰는 한빛미디어의 나는 리뷰어다 이벤트를 통해 책을 제공받아 작성했습니다.
예전과는 다르게 생활속에서 인공지능을 적용한 사례들이 점점 늘고 있다. 단순히 뭔가를 예측하거나, 이상점을 탐지하는 것에서 벗어나, 이제는 로봇을 제어하기도 하고, 인간이 생각하지 못했던 새로운 무언가를 만들어내기도 한다. 많은 사례들이 존재하기는 하지만, 내가 흥미롭게 본 사례 중 하나는 웹 최적화에 사용한 것이었다.
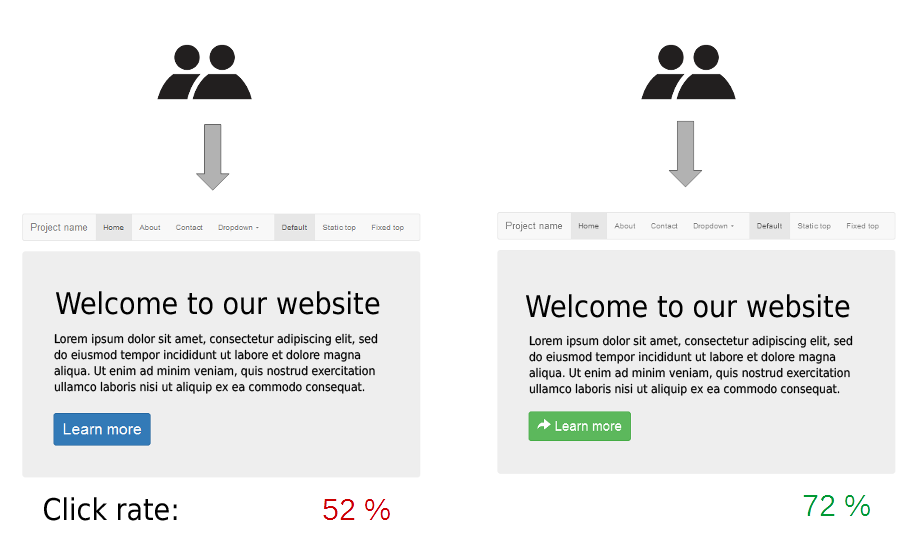
사실 간단한 원리이긴 하지만, 사용자에게 여러 가지 웹 UI에 대해서 보여주고, 이에 대한 Click Rate를 바탕으로 조금 더 친화적인 디자인을 찾아나가는 방식이다. 사람들이 어떤 구체적인 것에 관심을 가지는지는 설명하기 어렵지만, 위와 같이 Click Rate를 바탕으로 "아 오른쪽의 그림처럼 버튼이 조금 더 활성화되어 있는 것을 더 선호하는구나" 라는 경향을 얻어내고 이를 바탕으로 최적화를 수행하는 것이다.
이전에 얼핏 MS Research의 John Langford가 강의한 내용을 떠올려보자면, 그는 Vowpal Wabbit이라는 multiworld problem을 푸는데 최적화되어 있는 ML System을 사용해서 MSN 사이트의 UI를 개선하였고, 이를 통해서 약 25% 정도의 클릭율 상승의 효과를 가져왔다고 했다. 사실 클릭율이 뭐 그렇게 대단한 것인가 생각할 수도 있겠지만, 구글이나 네이버, 카카오같이 광고로 먹고 사는 회사들은 이 클릭율을 통해서 수익을 창출하고, 그 가치가 어마어마하다. (혹시나 Langford가 한 강의를 찾아보고 싶으면 링크를 참고해보면 더 많은 내용이 소개되어 있다.)

서두가 길긴 했는데, 이번에 소개하는 책은 뭔가 이론적인 내용이라기 보다는 머신러닝을 실제로 적용한 사례 중 웹 최적화에 특화된 내용을 다루고 있다. 사실 나도 딱 웹이란 단어가 책 제목에 있기에 "나는 웹에 대해서 잘 알지 못하는데..." 라는 생각을 가지고, 조금 읽기가 꺼렸었는데 실상 이 책이 담고 있는 내용을 살펴보니, 그런 걱정을 할 필요가 없다는 것을 알았다.
간단하게 말하자면, 이 책은 딱 웹에 대한 뭔가를 얘기하고자 하는 것이 아니라, 머신러닝을 적용한 사례 중 웹 최적화를 수행할 때에 초점을 맞춘 책이다. 책에서 다루는 내용은 다음과 같고,
중간 중간에 웹 최적화에 관한 예시들이 소개되어 있다. 사실 나도 강화학습에 관심을 가지고 공부하는 입장이긴 하지만, 이런 웹 최적화 문제도 강화학습 문제로 다뤄지는 것을 많이 봐왔다. 그도 그럴 것이 앞의 사례에서 보는 것처럼 어떤 환경이 주어졌을 때, 사용자의 반응을 보상이라고 여기고, 이 보상을 최대화할 수 있는 기법을 찾아가는 과정이 곧 강화학습 문제로 정의되는 것이다. 다르게 표현하면, 웹이라는 Context를 기반으로 하는 Bandit 문제가 되는 것이다. 그래서 이 책에서도 이런 문제를 해결하기 위한 다양한 샘플링 방법(Monte Carlo, Upper Confidence Bound, Thompson Sampling 등)들이 제시되어 있다.
내가 특히 흥미롭게 봤던 예시는 앞에서 소개한 샘플링 기법들을 활용해서 사람에게 최적화된 색상표를 찾는 방법이었다.

사실 이 사례는 어떻게 보면 책에서 말하고자 하는, 인공지능으로 웹 최적화를 수행할 때 이런 문제도 해결할 수도 있다는 것을 보여주는 좋은 사례인 것 같다. 이를 해결하는 과정이나 과정의 이해에 필요한 기반 지식들이 적절하게 잘 설명되어 있어, 딱히 이 책이 웹에 특화된 책이라기 보다는 실용서적에 가까운 느낌이 들었다. 책의 분량이 그렇게 많지 않음에도 적절하게 이해에 필요한 확률/통계 지식이나 알고리즘에 대한 이론적인 내용이 적절하게 잘 조합된 책이었다. 이와 더불어 결과에 대한 효과적인 시각화 기법들이 포함되어 있어, 이 책에 한정짓지 않더라도 다른 분야에 적용해보면 좋을만한 내용들이 담겨져 있었던 것 같다.
아마 서두에서 이야기했던 바와 같이 웹이란 말이 들어있어 거부감이 와닿았을 사람들도 있겠지만, 개인적으로는 이 책은 이론적인 내용과 웹에 대한 실용적 예시가 버물려진 인공지능 실용서이라고 생각한다. 혹시나 웹과 같은 Contextual Bandit Problem을 푸는 문제를 해결하고자 하는 사람이라면 이 책에 담겨진 내용들이 어떤 실마릴 찾는데 도움이 되지 않을까 싶다.
참고1: 사실 책에 대한 예제 코드가 딱 하나의 Jupyter Notebook으로 되어 있기 때문에 살펴보기 어려운 부분이 있다. 각 장별로 나눠서 소개했으면 좋았으련만 하는 아쉬움이 있다. 링크
참고2: 원저자 소개글
Shuhei Iitsuka
Shuhei Iitsuka is a creative technologist based in Tokyo. He makes new type of user experience by bridging the Web and machine learning technology.
tushuhei.com
(해당 포스트에서 소개하고 있는 "머신러닝을 활용한 웹 최적화" 책은 한빛미디어로부터 제공받았음을 알려드립니다.)
출처: https://talkingaboutme.tistory.com/entry/Book-Machine-Learning-with-web-optimization [자신에 대한 고찰]
안녕하십니까, 간토끼입니다.
오늘은 한빛미디어의 <나는 리뷰어다 2021>의 일환으로 받은 머신러닝을 활용한 웹 최적화에 대한 서평을 작성해보도록 하겠습니다.

제 블로그를 보신 분들은 아시겠지만, 제가 리뷰하는 대부분의 책들은 머신러닝, 혹은 딥러닝에 관련한 서적입니다.
그야말로 머신러닝 열풍이라고 할 수 있을 정도로 머신러닝에 관한 책이 많이 출판되고 있어요.
물론 개중엔 입문 서적의 비중이 제일 높긴 합니다만, 흥미로운 건 타 분야와 연계된 머신러닝 서적도 많이 출판되고 있다는 것이죠.
이 책은 그러한 책 중 하나입니다. 바로 웹 최적화(Web Optimization)에 머신러닝을 도입한 책이죠!
듣기만 해도 무슨 책일지 궁금한 이 책은 웹페이지를 보다 효율적으로 관리하면서 페이지의 유입을 효과적으로 늘리고 싶은 분들에게 추천하는 책입니다.
Q. 이 책은 어떤 책인가요?
웹 최적화에 머신러닝을 도입한 국내 최초의 책입니다.
우리는 일상에서 접하는 대부분이 인터넷과 연결된 4차 산업혁명 시대에 살고 있죠.
네이버, 다음, 구글 등 포털 사이트 없이는 어떻게 살 수 있을까 싶을 정도로 일상 속에서 수많은 웹페이지의 도움 덕에 살아가고 있습니다.
작게는 맛집 검색부터 생활에 필요한 정보, 여행지 가이드, 심지어 이렇게 제 블로그에서 유익한(?) 정보를 제공하는 것까지 다양한 웹페이지에서 수많은 정보를 다루고 있습니다.
이용자 입장에서 가장 중요한 건 '이 페이지가 내가 찾는 정보를 정확히 줄 수 있냐'는 것이죠.
그리고 서비스 제공자 입장에서는 당연히 이용자의 유입을 늘리기 위해서는 이 기준을 충족할 수 있어야 할 것이고요.
뭐 저처럼 자기 만족으로 블로그를 운영하는 사람들에게는 이용자의 유입 자체가 기쁜 일이겠지만,
이용자의 유입이 곧 구매로 이어지고, 이윤 창출로 이어지는 온라인 스토어 등에게 있어서는 단순히 유입만으로 끝나는 것이 아니라 구매까지 할 수 있도록 소비자의 유입 경로를 세밀하게 살펴보고 소비자에게 최고의 경험을 제공하는 것이 중요합니다.
하지만 이 웹페이지의 사용자는 개발자가 생각하는 것과는 다르게 반응하고 행동하죠.
왜냐하면 사용자는 너무나 많고 생각하는 것도 다양하기 때문에 어설픈 방법으로는 이 행동을 예측할 수 없게 됩니다.
이때 A/B 테스트로 대표되는 최적화 기술은 사용자의 선택을 예측함으로써 웹페이지를 보다 효과적으로 설계할 수 있는 기반이 됩니다.
예를 들어 특정 아이콘을 삽입하는 것이 좋을지, 안 좋을지에 대한 논의도 소비자의 클릭률 등의 특정 '지표'를 바탕으로 가설 검증에 활용해 더 나은 최적화 설계를 할 수 있도록 해주죠.
그래서 이 책은 통계학, 머신러닝이라는 수리적인 방법론을 이용해 최적화를 설명하고, 실제 파이썬 코드를 통해 구체적으로 알기 쉽게 정리한 책입니다.
목차를 설명하면 다음과 같습니다.
목차를 보면 아시겠지만 흥미로운 토픽들이 많습니다.
보시면 '베이즈 추론 기반 의사 결정'이 제일 흥미로운 토픽 같습니다.
베이즈 기반의 접근 방식이 요즘 핫하거든요.

하지만 내용이 좀 어렵긴 합니다. ㅋㅋ
아마 통계학을 잘 모르는 분들이시라면 마냥 읽기엔 어려움이 다소 있으실 거라 판단됩니다.
Q. 그럼 누구에게 추천하는 책인가요?
웹 최적화(Web Optimization)에 관심이 많거나 주업으로 삼고 계신 분들에게 최적화 성능을 높일 수 있도록 '머신러닝'이라는 핫한 주제를 도입한 책이므로 이에 관심이 있으신 분들에게 추천합니다.
특히 다음과 같은 주제에 관심이 많으신 분들에게 추천합니다.
● 베이즈 추론 기반 의사 결정
● 적은 양의 데이터를 활용해 효율적으로 가설 검증하는 방법, 선형 모델
● 통계 모델을 사용하지 않는 최적화 방법, 메타휴리스틱
● 다중 슬롯머신 문제(MAB)와 그 해법
● 베이즈 최적화로 대화형 최적화 문제 다루기
● 웹 최적화에서 해결되지 않는 문제들
아마 웹개발자 중 통계 베이스가 있으신 분들이 보셔야 할 겁니다.
사용되는 알고리즘 및 기법이 기초통계학 이상이기 때문이죠.
물론 챕터 4에서 통계 모델을 사용하지 않고 단순히 최적화 알고리즘만 사용하는 메타 휴리스틱에 대해서도 다루고 있습니다.
그럼에도 불구하고 전반적인 내용을 훑으시기 위해서는 통계 지식이 요구됩니다.

Q. 이 책의 장점은 무엇인가요?
머신러닝을 웹 최적화라는 낯선 분야에 도입했다는 것입니다!
통상 머신러닝이라고 하면 회귀 모형을 이용한 예측, 분류 모형을 이용한 분류 문제에만 관심을 갖게 되는데,
결국 머신러닝의 원리는 최적화에 기반하고 있거든요.
사실 여기서 다루고 있는 것도 머신러닝보다는 통계학에 좀 더 가깝지 않나 싶지만,
결국 머신러닝이 전산통계, 통계계산에 기반하고 있는 분야니깐요.
아무튼 웹개발을 하시는 분들 중 보다 획기적으로 웹페이지 설계를 시도해보고 싶으신 분들에게 추천하는 책입니다!
저도 기회만 된다면 해보고 싶을 정도네요.
감사합니다.
출처: https://datalabbit.tistory.com/110 [간토끼 DataMining Lab]

목차
CHAPTER 1 A/B 테스트부터 시작하자: 베이즈 통계를 이용한 가설 검정 입문
CHAPTER 2 확률적 프로그래밍: 컴퓨터의 도움을 받자
CHAPTER 3 조합 테스트: 요소별로 분해해서 생각하자
CHAPTER 4 메타휴리스틱: 통계 모델을 사용하지 않는 최적화 방법
CHAPTER 5 슬롯머신 알고리즘: 테스트 중의 손실에도 대응하자
CHAPTER 6 조합 슬롯머신: 슬롯머신 알고리즘과 통계 모델의 만남
CHAPTER 7 베이즈 최적화: 연속값의 솔루션 공간에 도전하자
CHAPTER 8 앞으로의 웹 최적화
APPENDIX A 행렬 연산 기초
APPENDIX B 로지스틱 회귀상에서의 톰슨 샘플링

머신러닝을 활용하는데 있어 저자의 설명을 보충하기 위해, 귀여운 그림으로 핵심 Keyword
관계 및 개념등을 시각화 해놓았다. 각 단원 별 그림을 찾아보는 재미도 종종 있었다.
본문 구성의 경우
1. 해당코드
2. 결과
3. 해석
으로 깔끔하게 구성된 모습을 볼 수 있었다.

각 단원 별 핵심 내용을 정리 Part에서 요약하였고, 이후 학습에 있어서 필요한 자료등을 수록해 놓아, 공부의 확장성을 높였다.
APPENDIX A 행렬 연산 기초
APPENDIX B 로지스틱 회귀상에서의 톰슨 샘플링
APPENDIX 부분에서는 위 책과 관련된 기본 수학 지식들을 수록해 놓아, 머신러닝과 관련된 수학지식을 어려워 하는 초보자를 배려하였다.
추천독자
· 웹 서비스 개발에 있어 사용자가 원하는 것을 A/B 테스트를 통해 사용자의 선택을 수치로 알고 싶은 프로그래머
· 사용자의 선택 이면에 숨겨진 데이터를 가설 검증에 활용해 최적화 설계를 수행하고자 하는 웹개발자
· 통계학과 머신러닝이라는 수학적 방법을 통해 최적화를 설명하고, 코드를 통해 학습하고 싶은 학생
· 웹 개발 최적화에 관심있는 분들께 위 책을 추천드립니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
오탈자 등록






