IT/모바일
비즈니스 데이터 과학
비즈니스 의사결정을 위한 통계학, 경제학, 인공지능의 만남
한빛미디어
번역서
판매중

- 저자 : 맷 태디
- 역자 : 이준용
- 출간일 : 2022-06-29
- 페이지 : 420쪽
- ISBN : 9791162245729
- 물류코드 :10572




-
더 나은 의사결정을 위한 필수 통계학, 경제학 개념부터 핵심 머신러닝 알고리즘까지
실무자를 위한 비즈니스 빅데이터 기술
비즈니스 분야에서 자주 언급되는 문제와 관련된 통계학, 경제학 개념 및 빅데이터 기술을 소개합니다. 이 책에는 아마존과 마이크로소프트에서 데이터 과학팀을 이끌고 시카고 대학교에서 계량경제학 및 통계학 교수로 재직하면서 데이터 과학 커리큘럼을 개발한 저자의 경험이 고스란히 담겨있습니다. 통계학, 경제학 개념부터 머신러닝 알고리즘까지 실무자가 알아야 하는 필수적인 내용들을 친절하게 설명하며 이를 R 프로그래밍 언어로 직접 구현하면서 모델링 기법의 목적과 사용법을 더 자세히 이해할 수 있게 돕습니다. 데이터 과학자, 데이터 엔지니어, 인공지능 개발자, 비즈니스 의사결정자 그리고 고급 통계학 지식을 얻고자 하는 사람에게 유용한 책입니다.

-
[저자] 맷 태디
아마존 부사장. 2008년부터 2018년까지 시카고 대학교 부스 경영대학원에서 계량경제학 및 통계학 교수로 재직하면서 데이터 과학 커리큘럼을 개발했습니다. 마이크로소프트의 수석 연구원(Head of Economics and Data Science, Business AI)과 이베이의 연구원(Research Fellow)을 포함하여 다양한 산업 분야에서 일한 경험이 있습니다.
[역자] 이준용
인공지능과 빅데이터 기술에 관심이 많은 연구원. 한국과학기술원(KAIST)에서 전자공학 박사학위를 받고, 일본 ATR IRC 연구소에서 인간-로봇 상호작용에 대해 연구했으며, 미국 아이오와 주립대학교에서 대사회로 관련 데이터베이스를 구축했습니다. 2014년부터 2021년까지 미국 퍼시픽 노스웨스트 국립연구소에서 다양한 생명과학 연구에 참여했습니다. 현재는 한 바이오텍 기업에서 수석 데이터 과학자로 암 진단과 관련된 일을 하고 있습니다.
-
CHAPTER 0 들어가며
두 도표에 대한 이야기
빅데이터와 머신러닝
계산
CHAPTER 1 불확실성
1.1 빈도주의 관점에서의 불확실성과 부트스트랩
_알고리즘 1 | 비모수 부트스트랩
_심화학습 | 편향된 추정량과 부트스트랩 사용
_알고리즘 2 | 신뢰구간을 위한 비모수 부트스트랩
1.2 가설 검정과 거짓 발견 비율 조절
_알고리즘 3 | BH FDR 제어
_심화학습 | BH 알고리즘이 작동하는 이유
1.3 베이지안 추론
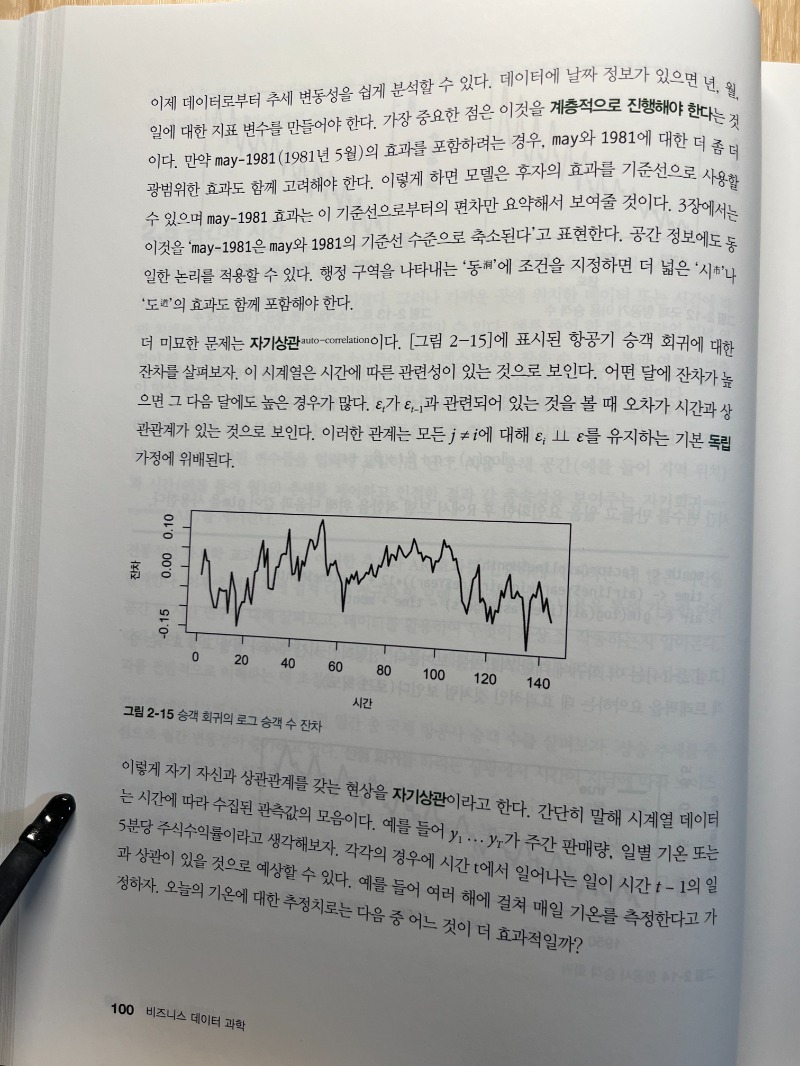
CHAPTER 2 회귀
2.1 선형 모델
2.2 로지스틱 회귀
2.3 편차와 가능도
2.4 회귀 불확실성
2.5 공간과 시간
CHAPTER 3 정규화
3.1 표본 외 성능
_알고리즘 4 | K-폴드 표본 외 검증
3.2 정규화 경로
_알고리즘 5 | 전진 단계별 회귀
_알고리즘 6 | lasso 정규화 경로
3.3 모델 선택
_알고리즘 7 | K-폴드 CV
_알고리즘 8 | K-폴드 CV lasso
3.4 lasso에 대한 불확실성 정량화
_알고리즘 9 | lasso 신뢰구간을 위한 모수적 부트스트랩
_알고리즘 10 | √n 학습에서 서브샘플링 CI
CHAPTER 4 분류
4.1 최근접 이웃
_알고리즘 11 | K 최근접 이웃
4.2 확률, 비용, 분류
_알고리즘 12 | 맵리듀스 프레임워크
4.3 다항 로지스틱 회귀
4.4 분산 다항 회귀
4.5 분산과 빅데이터
CHAPTER 5 실험
5.1 무작위 대조 시험
5.2 유사 실험 설계
5.3 도구 변수
_알고리즘 13 | 2SLS
CHAPTER 6 제어
6.1 조건부 무시가능성과 선형 처리 효과
6.2 고차원 교란 조정
_알고리즘 14 | LTE lasso 회귀
6.3 표본 분할과 직교 머신러닝
_알고리즘 15 | LTE를 위한 직교 머신러닝
6.4 이종 처리 효과
6.5 합성 제어
_알고리즘 15 | 합성 제어
CHAPTER 7 인수분해
7.1 클러스터링
_알고리즘 17 | K-평균
7.2 요인 모델과 PCA
_알고리즘 18 | 주성분 분석
7.3 주성분 회귀
_알고리즘 19 | 주성분 (lasso) 회귀
7.4 부분 최소제곱법
_알고리즘 20 | 주변 회귀
_알고리즘 21 | 부분 최소제곱법(PLS)
CHAPTER 8 데이터로서의 테스트
8.1 토큰화
8.2 텍스트 회귀
8.3 토픽 모델
_알고리즘 22 | 희소 데이터를 위한 PCA
8.4 다항 역회귀
8.5 협업 필터링
8.6 워드 임베딩
CHAPTER 9 비모수
9.1 의사결정트리
_알고리즘 23 | CART 알고리즘
9.2 랜덤 포레스트
_알고리즘 24 | 랜덤 포레스트(RF)
_알고리즘 25 | 경험적 베이지안 포레스트(EBF)
9.3 인과 트리
_알고리즘 26 | 인과 트리(CT)
9.4 반모수와 가우스 프로세스
CHAPTER 10 인공지능
10.1 인공지능이란 무엇인가?
10.2 범용 머신러닝
10.3 딥러닝
10.4 확률적 경사하강법
10.5 강화 학습
10.6 상황에 따른 인공지능
-
아마존 수석 이코노미스트(부사장)의 노하우와 사례로 가득한 실무 중심의 비즈니스 데이터 과학
오늘날에는 머신러닝과 통계학, 데이터 기반의 사회과학 및 경제학과 같은 분야에서 끊임없는 지적 융합이 일어나고 있으며, 이러한 융합은 데이터 분석의 질을 높여줍니다.이 책은 최선의 데이터 분석 방법을 설명하기 위해 머신러닝과 통계학 그리고 경제학을 융합합니다. 머신러닝과 통계학으로 자동화 및 확장 방법을 배우고, 경제학에서 인과관계 및 구조 모델링을 위한 도구를 가져오며, 이러한 방법들이 비즈니스 의사결정과 어떤 관련이 있는지 설명합니다. ‘무슨’ 일이 일어났는지가 아니라 ‘왜’ 이런 일이 발생했는지에 초점을 맞추어 설명하기 때문에 다양한 모델의 핵심 개념을 쉽게 이해할 수 있습니다. 저자가 학생들을 가르치며 얻은 노하우와 이베이, 마이크로소프트, 아마존에서 경험한 사례를 여러분의 실무에 적용해보세요!
주요 내용
- 비즈니스 의사결정에 필요한 통계학, 경제학 이론과 머신러닝 알고리즘
- 텍스트 분석, 가격 결정 및 수요 추정, A/B 실험, 고객 행동 분석의 사례
- 머신러닝 도구를 사용하여 비즈니스 의사결정을 내리는 방법
- 인공지능으로 비즈니스 문제를 해결하는 방법
추천사
이 책은 데이터 활용의 기초가 되는 통계 지식을 빈틈없이 친절하게 설명하며 실제 애플리케이션, 기술, 인사이트를 가득 담고 있다. 대부분의 머신러닝 책과 다르게 ‘상관관계는 인과관계와 다르다’는 문제를 다루고, 데이터로부터 신뢰할 수 있는 정보를 추출하는 방법을 제공한다.
프레스턴 맥아피(전 마이크로소프트 수석 경제학자 겸 부사장,
_야후 수석 경제학자 겸 부사장, 구글 연구이사, 캘리포니아 공과대학 교수 겸 임원)
맷 태디는 시카고에서 스타 강사로 일하던 시절의 경험, 마이크로소프트와 아마존에서 데이터 과학팀을 이끌었던 경험을 바탕으로 기업에 데이터 기반 의사결정 프로세스를 도입하고자 하는 MBA와 엔지니어를 위한 훌륭한 책을 집필했다. 현대 통계, 머신러닝 알고리즘, 사회과학 인과 모델의 핵심 개념을 누구나 요점이 무엇인지 알 수 있도록 쉽게 썼다. 이 책은 이 분야의 대표적인 교과서가 될 것이다.
휘도 임번스(스탠포드 경영대학원 경제학 교수,
_『Causal Inference for Statistics, Social, and Biomedical Sciences』의 공동 저자)
이 책은 수많은 데이터 과학 교과서 중에서 두각을 나타내며, 현실의 기본적인 비즈니스 문제를 해결하기 위해 다른 분야의 주제를 고려한다. 정확한 예측은 그 자체가 목적이 아니라 최선의 행동을 취하기 위한 수단이다. 맷 태디는 이러한 내용을 명확하고 읽기 쉽게 설명한다. 데이터 과학에 대한 배경지식이 없지만 예측, 인과관계, 의사결정과 관련된 최신 기술을 알고 싶은 사람, 이러한 기술을 실제 문제에 적용하는 데 관심이 있는 사람에게 이 책을 추천한다.
_존 매콜리프(볼레온 그룹의 공동 창립자 겸 최고 투자 책임자)
맷 태디는 최고의 강사다. 중요한 아이디어를 명확하게 전달하는 그의 능력이 이 책에서 빛을 발한다. 기업에서 데이터를 사용하는 방식을 개선하기 위해 컴퓨터과학, 경제학, 통계학의 인사이트를 결합하는 능력 또한 우수하다. 모두가 이 책을 읽어야 한다.
옌스 루트비히(맥코믹 재단 사회 서비스 행정,
_법률 및 공공 정책 교수, 시카고 대학교 범죄 연구소 소장)
가장 흥미로운 최신 데이터 과학 책이다. 빈틈없는 구성으로 놀라움을 선사한다.
더크 에델부에텔(퀀트, 『Seamless R and C++ Integration with Rcpp』의 저자,
_일리노이 대학교 어배너-섐페인 통계학과 임상 교수)
데이터 분석을 바탕으로 더 나은 의사결정을 내리는 것에 관심이 있는 사람이라면 꼭 읽어야 할 책이다.
_에밀리 오스터(브라운 대학교 경제학 교수, 『Expecting Better』과 『Cribsheet』의 저자)
맷 태디는 훌륭한 방법으로 데이터 과학의 복잡한 아이디어를 설명한다. 이제 이 책을 통해 그가 제시하는 방법을 모두가 볼 수 있게 되어 기쁘다.
_제시 셔피로(조지 S., 낸시 B. 파커 브라운 대학교 경제학 교수)
이 책은 최근 비즈니스에서 데이터와 관련된 문제를 해결하는 데 중요한 수학적 이론과 실용적인 방법을 소개한다. 맷 태디는 데이터 과학 분야의 세계적인 리더이자 독특한 관점을 가진 사람이다. 이 책은 그의 엄격한 학문적 시각과 비즈니스 경험에서 얻은 지혜를 모두 반영한다.
_데이비드 블레이(컬럼비아 대학교 컴퓨터과학 및 통계학 교수)
-
-
오랜만에 굉장히 이론의 비중이 높은 신간 데이터 과학 책을 만났다. 읽기 쉽게 쓰여진 책들도 좋지만 개인적으로 이렇게 글이 빡빡하고 넓은 범위의 내용을 꼼꼼하게 써놓은 책을 더 좋아한다. 많은 내용이 담겨 있기 때문에 하나의 개념에 대해 깊게 들어가는 책은 아니지만 다양한 영역에서의 데이터 과학에 대해 학습해 볼 수 있는 좋은 책이었다. 입문서로써도 괜찮지 않을까 생각되는 책이다만 밀도 높은 책을 싫어한다면 조금 경기를 일으킬 수는 있겠다.

『비즈니스 데이터 과학』 비즈니스 의사결정을 위한 통계학, 경제학, 인공지능의 만남
저자 소개를 꼭 해야겠다. Matt Taddy. 아마존의 부사장으로 시카고 경영대학원에서 통계학 교수로 재직하면서 본인만의 데이터 과학 커리큘럼을 개발했다고 한다. 그 내용이 온전히 이 책에 담겨 있을 것을 기대하고 보니 왠지 더 믿음이 갔다. 어쩐지 책을 보는데 수업을 듣는 느낌을 받더라니...

이 책이 경영대학원의 데이터 과학 수업을 위한 커리큘럼을 만든 교수이자 한 회사의 대표가 저술한 것임을 알고 읽으면 확실히 다른 개발 서적과는 조금 다른 관점에서 쓴 책임을 알 수 있다. 저자는 생각하는 대상 독자로 단순히 개발자들만을 위해 쓰지 않았다. 더 크게, "과학자" 를 대상으로 했으며, 그 안에는 컴퓨터 과학자 뿐만 아니라 생물학, 물리학, 기상학, 경제학 등 여러 분야를 포함한다. 최소한의 프로그래밍 경험만 있으면 읽을 수 있는 수준으로 작성되었으며 데이터 과학에 대한 비전문가들도 경력 전환을 위해 쉽게 학습할 수 있도록 하기 위해 노력했다고 한다.

경영대학원 교수님 출신 답게 시작은 미국의 대표적인 지수 S&P500 에 대한 내용을 보여주면서 시작한다. 이 책을 계속 따라가다보면 다양한 데이터를 직접 다뤄보고 시각화도 해보면서 많은 인사이트를 얻을 수 있을 것 같다.

초반의 내용은 통계학의 내용이 주를 이룬다. 학생 시절에 확률, 통계 등을 잘 공부했다면 아주 쉽고 재밌게 넘어갈 수 있겠지만, 역시 언제봐도 헷갈리고 어렵다. 처음에 공부를 해서 잘 이해했다고 생각한 뒤 프로그래밍만 주구장창 하다보면 언제부턴가 깊은 개념은 잊고 단순히 사용 방법과 결과만 알고 쓰게 되는데, 이런 이론서들을 끼고 다니면서 복습하는 습관을 가진다면 정말 어려운 문제를 만났을 때 스스로 문제를 해결하는 능력을 많이 키울 수 있게 되지 않을까.
경제학자 답게 확률에 대한 내용들을 단순히 수학적인 설명만으로 하지 않고 경제학에서 사용하는 용어들을 적절하게 섞어서 표현한다. 확률과 비용 그리고 분류가 한 소단원의 제목으로 들어있는 것은 확실히 개발자 입장에서 새롭다.

데이터를 분석해보고 그 알고리즘들을 하나씩 공부해보기도 하고 아래 그림처럼 시각적으로 표현하면 완전히 새로운 인사이트를 얻는 경우가 종종 있다. 책이 프로그래밍을 많은 비중을 다루고 있지는 않지만 충분히 많은 코딩 방법들도 익힐 수 있어서 다른 데이터를 응용해 볼 때도 많은 도움을 얻을 수 있다.

인공지능이나 머신러닝에 대한 것을 기대하고 이 책을 봤다면 조금 실망할지도 모르겠다. 챕터 10 이 되면 인공지능을 다루고 있긴 하지만 대부분 간단한 예와 용어에 대한 설명만으로 구성되어 있다. 40 페이지 정도의 아주 적은 양이라 인공지능에 대해 공부하는 책은 아니라고 봐야한다. 다만 이 책을 읽고 나면 다른 인공지능, 머신러닝 책들의 초반에 항상 나오는 기본적인 개념들이 상당히 쉽게 느껴지게 될 것이다. 쉬워서 기본서가 아니라 정말 그 학문들에 대한 기반이 담긴 책이다.

오랜만에 많은 시간을 두고 읽어보고 싶은 책을 받았다. 가만히 책처럼 읽어보고 하나씩 정리해가면서 봐야겠다. 2023년에는 나도 새로운 커리어를 만들 수 있지 않을까.
끝.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
-
데이터 분석 역량에 본질은 '의사결정의 근거'를 최대한 객관적으로 만드는 목표를 달성하는 것이다.
이때 사용되는 도구로는 통계학, 경제학, 머신러닝등이 있다.
일반적으로 이러한 책들은 '코딩'중심이다.
왜? 이런 분석을 쓰는지,
어떻게? 이런 분석을 만들게 되었는지
최종적으로 추구하는것과 발전방향은 무엇인지에 대해 잘 나와있지는 않다.
평소 코딩을 하면서 '본질적으로' 이 분석을 왜 쓰고, 어떻게 나왔는지 배우고 싶다면 추천하고 싶은 책이다.
개인적으로 처음 빅데이터에 대해 공부할때, 통계부분까지는 어렵진 않았는데
회귀쪽부터 내용의 확신을 가지지 못하고 코딩을 했었는데
이 책을 통해서
선형 모델, 로지스틱 회귀, 편차와 가능도, 회귀 불확실성, 공간과 시간 등을 공부하여
어두웠던 지식에 빛을 밝힐 수 있었다.
다만, 기초 통계지식이 없다면 해당 책을 읽기가 어려움으로, 통계관련 기초 공부를 학습 후 읽는 것을 추천한다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
-

이 책에 대해 간단히 말하자면, 결코 데이터를 만만하게 보지 않는 사람들을 위한 책이라고 생각합니다. 비즈니스 데이터 과학이라는 책의 제목에서 알 수 있듯 통계학, 경제학, 머신 러닝 등에서 활용되는 다양한 데이터의 개념들을 보다 전문적으로 학습할 수 있는 도서입니다. 특히 저자인 맷 테디는 경제학과 통계학을 전공하며 시카고 대학교에서 데이터 과학 커리큘럽을 직접 개발한 경험이 있는데요. 데이터 과학의 권위자가 집필한 도서인 만큼 그 내용과 범위가 꽤 깊이 있게 다뤄진다는 점이 흥미로웠습니다. 해당 도서는 크게 5가지의 특징을 가지고 있습니다.
- 비즈니스 의사 결정에 필요한 통계학, 경제학 이론과 머신러닝 알고리즘
- 텍스트 분석, 가격 결정 및 수요 측정, A/B 실험, 고객 행동 분석의 사례
- 머신러닝 도구를 사용하여 비즈니스 의사결정을 내리는 방법
- 인공지능으로 비즈니스 문제를 해결하는 방법
- 풍부한 R 코드 예제
다음과 같이 간략한 특징을 짚어 보았는데요, 프로그래밍 언어인 R을 활용하여 모델링과 관련한 내용을 더욱 자세히 설명해주고 있어 데이터를 통해 비즈니스에 인사이트를 얻고 싶은 분들에게 추천드리고 싶은 책입니다. 어려운 데이터의 실습 영역들을 다루며 친절하게 설명을 하고 있지만, 프로그래밍 언어를 다룬다는 점과 수학적 지식이 어느 정도 요구된다는 점에서 보다 전문적인 지식을 쌓고 싶고, 깊이 있게 공부를 해나가고 싶은 분들이 읽으면 정말 좋을 것 같습니다. 항상 현업에서도 데이터를 가지고 어떻게 하면 인사이트를 뽑아내고, 제대로 분석을 할 수 있을 지 항상 고민을 해왔는데요, 다양한 알고리즘은 물론 친절한 실습 설명을 통해서 데이터와 한층 더 가까워질 수 있는 도서였던 것 같습니다.
-

[비즈니스 데이터 과학]
조직의 성장을 위해서 데이터 과학자들이 겪어야 하는 고난은 꽤 많이 있고, 개인의 단계에서 할 수 있는 노력을 몇개만 꼽자면 다음과 같습니다.
1. “비즈니스”라는 단어의 인지
2. 코드 멍키를 넘어, “제대로 된” 분석을 위해 깔려있는 수리/통계의 이론적이해
3. 실제 데이터 과학의 효과를 보여주는 좋은 예시
4. “바퀴를 재발명”하지 않고도, 원하는 분석을 할 수 있는 프로그래밍
이를 채워줄 수 있으리라 기대되는, 데이터 과학에 대한 내용들을 다루는 책은 꽤 많이 있고, 좋은 책도 정말 많습니다.
그런데 경험상 이 책들에서는 아래와 같이 “데이터 과학자들이 필요로 하는 역량” 중 1개의 관점에만 집중적으로 다뤄지곤 합니다.
그런데, 이 책의 저자인 "멧 태디"는
- NASA RA, 통계학 교수 (학계)
- MS의 연구팀 Head, E-Bay 연구원 (산업계)
- Amazon VP (비즈니스)
와 같은 타이틀로 다양한 역량을 이미 보인 분. 아래에 책의 저자의 말 일부를 인용하는 것으로
책이 여러가지를 다뤄줄 수 있다는 이야기를 하고 싶습니다.
"
필자는 이 분야에서 10년 넘게 일했다.
…
이 과정에서 비즈니스 문제를 이해하고 직접 빅데이터 분석을 실행할 수 있는
다방면의 지식을 가진 사람들이 어떻게 성장하는지 지켜봤다.
…
필자는 이들의 성장을 돕기 위해 이 책을 집필했다.
"
[책의 구조 및 특징]
이 책은 주제를 기준으로 3개의 큰 덩어리로 나눠볼 수 있습니다.
- 통계 & 머신러닝 (1–4장, 7–9장)
- 실험 (5–6장)
- 딥러닝 개론 (10장)
다만 딥러닝에 대한 이야기는 그렇게 까지 깊거나 어려운 내용은 아니고 “개론” 이라 표현한 것처럼
살짝만 다뤘다고 생각하기에 만약 스스로가 데이터 과학자라기보단 ML Engineer에 가까운 역할을 하고,
관련된 지식들을 필요로 한다면 이 책보다 다른 책이 더 도움이 될 것 같습니다.
“통계 & 머신러닝”에서는. 회귀, 분류, 정량화, 요인 분해 (인수분해라고 번역 됨), 텍스트 분석과 같이 다른 도서에서도 많이 다뤄지는 주제들을 다루고 있습니다.
다만 경제학의 관점에서 바라보는 부분이 있다는 것과 동시에 통계적으로 조금 빡세게 다루고 있다는 점을 차별점으로 볼 수 있습니다.
“실험”에서는. AB테스트에 전제되는 이론과 실행하는 예시 그리고 실험에 영향을 주는 side effect들을 “통제” 하는 내용들을 다루고 있습니다.
[구매를 고민하게 하는 몇몇 특징]
- 교수님 특유의 “어려운” 문장:
"그러나 처리가 더 복잡해지고 연구 기간이 길어질 경우 처리군은 결과에 영향을 미치는 체계적인 방식으로 달라진다."
와 같이 정신을 잠깐만 놓쳐도 의도를 알기 어려운 표현들이 도서 전체에 많이 있습니다. (원어가 어려운지 번역이 어렵게 된 건지는 모르겠음)
- R 기반 코드: 개인적으로는 좋아하지만 많은 산업계에서 R보다는 Python이 활용 되고 있다는 것을 감안했을때
이론을 넘어서서 코드를 직접 본인의 문제에 적용해보려고 하는 사람들에게는 장벽이 될 수도 있습니다.
- 비즈니스라는 탈을 쓴 통계학 교재: 사람에 따라 오히려 더 좋을 수도 있는 부분인데,
아무래도 사용 할 수 있는 데이터의 제한이 있다보니 MBA, 경제 경영학과 같은 곳에서 언급될 정도의
비즈니스 관점의 레퍼런스는 아닌 실생활의 예시를 다뤘다 정도의 이 책을 통해서 비즈니스를 배울 수 있다 라고 하긴 어렵습니다.
마찬가지로 프로그래밍 관점에서 배울 것이 많은 코드가 있다고 보기도 어렵습니다.
그러나 통계학의 관점에서는 완전 기본이 되는 전제들 까지 깊게 다루는 책으로 만약
본인이 이러한 통계의 이론적 부분에 대한 아쉬움이 있다면 이 책은 많은 도움이 될 수 있습니다.
[그래서]
만약 본인이 “학원” 출신으로 얕게 프로그래밍 정도만 배워 분석에 필요한 전제와 이론들을 든든히 채우고 싶다면 이 책은 아주 도움이 됩니다.
만약 본인이 “대학원” 출신으로 이론은 있지만, 본인의 연구 도메인 외에 다른 쪽에서의 데이터과학 예시를 알고 싶다면 이 책은 도움이 됩니다.
만약 본인이 “데이터 과학자”로 이미 업무를 하고 있고, 그로스와 같은 전략 관점보다 실험, 분석과 같은 테크닉쪽에서 성장하고 싶은 분이라면 이 책은 도움이 됩니다.
만약 본인이 “PM”과 같이 다른 포지션에서 데이터 과학을 시작하거나, 데이터 과학자와 같이 업무를 해야하는 사람이라면 이 책은 도움이 되지 않습니다.
마찬가지로 비즈니스적 역량을 키우고 싶은 분들에게도 이 책보다 더 도움이 될 경영 도서가 많다고 생각합니다.
한빛미디어의 나는 리뷰어다 활동을 위해 책을 제공받아 작성된 서평입니다.
-
올해 마지막 서평을 쓸 책은 `비즈니스 데이터 과학`입니다. 요즘 데이터 과학 분야 책을 보면 모든 데이터는 `인공지능/딥러닝`으로 이어지던 흐름에서 `ML/DL`과 별개로 활용 가능한 데이터 가공 및 모델링 등 분화하는 듯 합니다. 이 책도 회귀로 시작해서 인공지능을 끝을 맺습니다. 인공지능 모델들이 현재까지는 데규모 데이터를 다루는데 효과적인 것은 현재까진 사실에 가까우니까요.
데이터 과학를 다루는 많은 책들이 대부분 `Python` 기반의 코드를 다루는 것과 대조적으로 개인적으로는 오랜만에 만나는 `R`로 쓰인 책입니다. 아무리 `Pyhton`이 쉽고 데이터 사이언스가 견인해서 컸다고는 하지만 통계계통 사용자들의 안식처인 `R`과 `matlab`의 규모를 무시할 수 없는 듯 합니다.
`R`로 쓰여졌지만 코드를 중심으로 전개되는 책이 아니어서 `R`과 친하지 않으셔도 전혀 책을 읽고 공부하시는데 지장이 없을 듯 합니다. 물론 특정 언어의 기본 문법만 익히셨다면 언어 공부를 더 하긴 하셔야 코드가 이해가 갑니다.
수식과 그림이 데이터를 다루는 인사이트를 가져옵니다. 여러분이 아무리 숫자에 대한 감각이 좋으셔도 서로 다른 스케일을 가지고 있는 고차원 데이터를 보고 정규화나 시각화 없이 데이터를 이해한다는 것은 사실 불가능에 가깝다고 생각 됩니다. 가능하신 분은 이 책 구매를 고민하시면서 이 글을 읽지도 않으실테지만요.
전형적인 기술서의 번역체를 가지고 있지만 다듬어진 번역체라 읽는데 거슬리는 부분은 없었습니다. 책을 읽다가 멈추는 대부분의 장소는 수식 위 였고, 수식의 첨자가 어떤 함의를 가지고 있는지 이해를 위해서 였습니다.
`R`의 기반을 두고 계시면서 데이터 과학을 좀 더 공부해보고 싶었던 통계학과나 비전공자라면 입문서적으로 추천드릴 수 있습니다. 수식을 배제하지 않고 적극적으로 사용 중이기 때문에 수학과 전혀 관련없던 전공을 하셨다면 애로사항이 있으실 수 있지만, 데이터 과학을 위해선 시기의 차이일 뿐 수학은 하셔야 하기에 겸허히 받아드리셔야 합니다.
내년에도 서평을 계속 이어 갈지 아직 알 수는 없지만 내돈내산 서평도 꾸준히 이어가 보도록하겠습니다.
---
한빛미디어 `2022 도서 서평단 "나는 리뷰어다"`의 일원으로 도서를 제공받아 작성한 리뷰입니다.
-
데이터 분석을 전공하지 않으면서 이를 공부하려면 편파적으로만 알기 쉽고, 또 깊이가 부족하다고 느껴지기도 한다. 사실 이 책은 디자인도, 책의 내용도 전공 도서 같은 느낌이어서 거부감이 들었었다. 하지만 하나하나 공부할수록 대충 이해만 하고 넘어갔거나 구글에서 얕게 공부했던 개념들이 새롭게 이해되는 느낌이 들어서 앞으로도 좀 더 이 책을 공부해보려고 한다.
-
비즈니스 데이터과학
비즈니스 의사결정을 위한
통계학, 경제학, 인공지능의 만남

멧 태디 지음 / 이준용 옮김 / 한빛미디어
아마존 수석 이코노미스트(부사장)의 노하우와 사례로 가득한 실무 중심의 비즈니스 데이터 과학
오늘날에는 머신러닝과 통계학, 데이터 기반의 사회과학 및 경제학과 같은 분야에서 끊임없는 지적 융합이 일어나고 있으며, 이러한 융합은 데이터 분석의 질을 높여줍니다.
이 책은 최선의 데이터 분석 방법을 설명하기 위해 머신러닝과 통계학 그리고 경제학을 융합합니다.
머신러닝과 통계학으로 자동화 및 확장 방법을 배우고, 경제학에서 인과관계 및 구조 모델링을 위한 도구를 가져오며, 이러한 방법들이 비즈니스 의사결정과 어떤 관련이 있는지 설명합니다.
‘무슨’ 일이 일어났는지가 아니라 ‘왜’ 이런 일이 발생했는지에 초점을 맞추어 설명하기 때문에 다양한 모델의 핵심 개념을 쉽게 이해할 수 있습니다.
저자가 학생들을 가르치며 얻은 노하우와 이베이, 마이크로소프트, 아마존에서 경험한 사례들이다.


비즈니스 분야에서 데이터과학의 활용도는 날로 증가하고 있다.
다양한 적용 케이스를 실제로 R을 이용하여 분석 예측한 결과를 소개하고 있다.
현업에서 바로 적용 가능한 사례들일 수 있다.
참고하여 자신의 비즈니스 분석 예측 분야에 적용할 수 있으면 더 바람직한 결과를 얻지 않을까?
통계학을 접하지 않은 독자가 읽기에는 용어 자체가 생소할 수 있다.
그러나 너무 기피할 필요는 없겠다. 저자의 의도를 역자가 이해하기 쉽게 설명을 하고 있다.
편집자는 수고가 많았겠구나 하는 생각이 절로 든다. 통계학 용어는 강조를 하여 쉽게 볼 수 있게 하였다.
‘구슬이 서 말 이라도 꿰어야 보배!’ 라 한다.
자신의 비즈니스 분야에 적용하여 좋은 성과를 얻는것은 독자의 몫일 것이다.
2023년 새해엔 좋은 비즈니스 성과를 얻기 기원한다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
#비즈니스_데이터과학 #데이터과학 #비즈니스 #의사결정 #통계학, #경제학, #인공지능 #만남 #멧_태디 #이준용 #한빛미디어
-

저자인 맷 태디는 아마존 08년부터 18년까지 시카고 대학교 부스 경영대학원에서 계량경제학 및 통계학 교수로 재직하였으며, MS의 수석 연구원과 이베이의 연구원을 포함하여 다양한 산업 분야에서 일한 경험이 있으며 현재는 아마존 부사장으로 재직하고 있다.
이 책은 비지니스에서 데이터 관련 문제를 해결하는데 중요한 수학적 이론 및 실용적인 방법들을 소개하고 있다. 저자의 특별한 시각과 비지니스 경험에서 얻은 지혜들을 담고 있기에, 많은 인사이트들을 얻을 수 있을 것이다.
이 책은 데이터 기반 회사에서 데이터 과학자로 일하려는 사람에게 촛점을 맞춰 저술되었다.
이 책을 통하여 비즈니스 정책에 중요한 영향을 미칠 변수를 식별하고, 정책 변경에 따른 재동의 반응을 파악하기 위한 SNS 데이터를 수입하여 분석할 수도 있다.
과거 데이터에서 패턴을 찾는 것은 유용하기 때문에 이 책에서 여러가지 패턴 인식 방법에 대해 배우겠지만 비즈니스 문제에 대해서 더 깊은 분석을 위해서는 '무슨 일'이 일어났는지보다 '왜' 이런 일이 발생했는지를 파악해야하며, 이 책에서는 상관관계 뿐만 아니라 인과관계 분석에도 도움이 되는 기법들을 설명하고 있다. 주류 데이터 과학보다는 경제학에 더 가깝기에 실무에 실질적인 도움이 될 것이다.
솔직히 말해 개인적으로 친근함이 느껴지는 책은 아니다. 시작부터 수두룩하게 나열되는 수식들과 어려운 용어들, 도표들에 정신을 압도당한다.
아무래도 비전공자나 입문자들을 대상으로 하는 가벼운 책이 아니다보니 그런 것 같다.
의사 결정과 관련된 최신 기술을 알고싶고, 신기술을 문제에 적용하는데 관심이 있고, 데이터 분석을 바탕으로 더 나은 의사 결정을 내리는 것에 관심이 있는 사람에게는 강력히 추천할만 하다.
챕터는 크게 11개로 나뉘며 챕터 0 '들어가며'를 제외하면 모두 10개의 챕터로 이루어져 있다.
- 불확실성
- 회귀
- 정규화
- 분류
- 실험
- 제어
- 인수분해
- 데이터로서의 텍스트
- 비모수
- 인공지능

[한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.]
-

이책은 R을 배우기 위한 책은 아니란는 내용을 저자의 설명에서 해주고 있다.
책내용에서도 r에 대한 부가적인 설명은 없어서 초보자들에게 는 좀 내용이 어려울 수 있다.
머신러닝에 기조가 되는 통계학에 대해 설명하고 있는 책이라 기존 머신러닝보다는 좀더 수학적으로 접근하는 느낌이었다.

실제 머신러닝에서 필요한 알고리즘들에 설명들이 통계분석에서도 내용이 설명되어서 해당내용을 좀더 통계학적으로 접해보고 싶은 사람은 이책이 맞을것같는 생각이 들었다.
1. 실습
나는 rstudio online에서 실습을 했고 일반 desktop 에서 설치된 화면과 크게 다르게 불편한 점은 없었다.
좀 속도는 좀 느린편인거 같다.
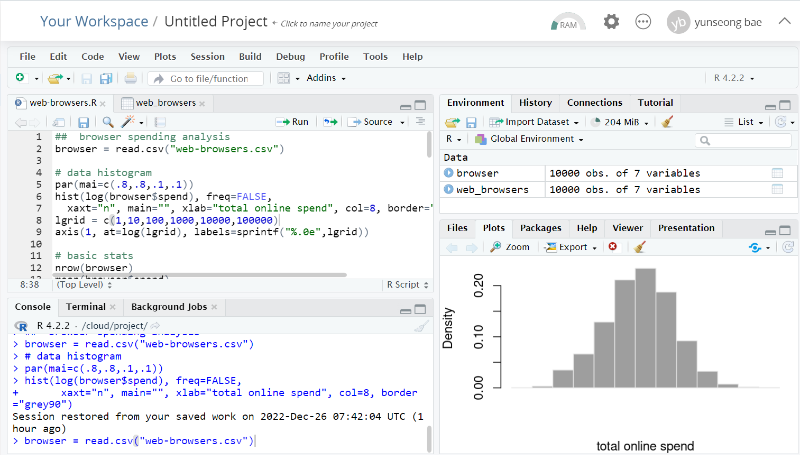
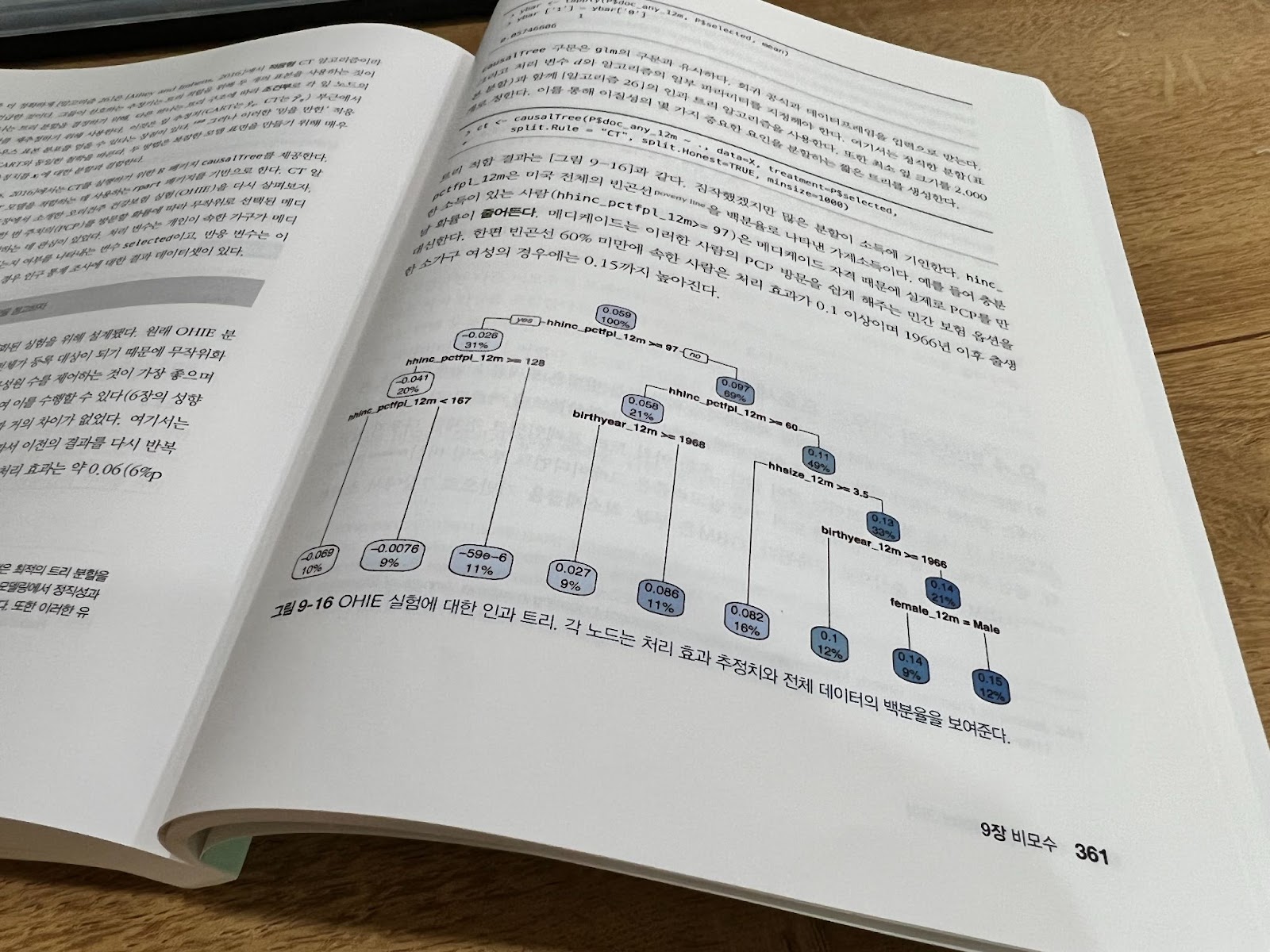
왼쪽 상단은 실습창으로 결과는 아래 하단 콘솔에 표시되고 오른쪽윈도우에 차트나 기타 뷰어등이 있다.
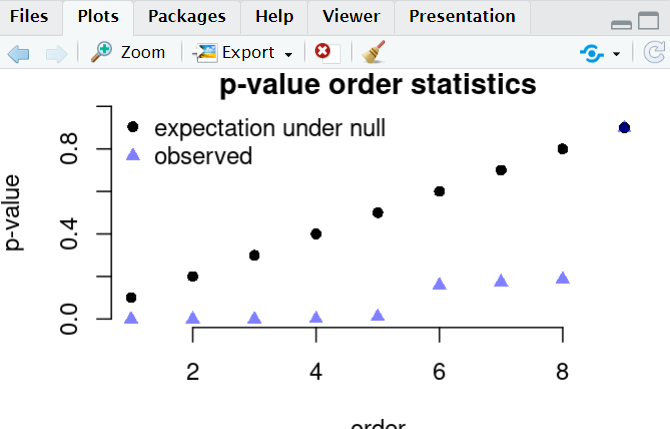
9개의 공변량을 사용한 지출 희귀 분석에 fdr 제어를 위한 bh 알고리즘. 9개의 p값은 해당 순위에 따라 표시되며 선의 기울기는 0.1/9이다.
이선 아래 5개의 p값은 유의미하며, 이러한 방식으로 유의성을 정의하는 절차는 10%의 fdr을 갖는다.
이처럼 간단하게 불확실성에 대해 알아 보았다.
내용은 좀 어려울 수 있지만 기존에 통게와 머신러닝을 학습한 독자에게는 유용한 내용일 수 있다.
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
-

전문가만이 접근이 가능했던(물론 이 말은 현재도 유효하다.) 데이터 분석이 이제는 다양한 프로그램의 개발로 이전에 비해 데이터 분석에 대한 접근이나 방식이 많이 다양해졌다. 그래서 이전에는 여러명의 전문가가 팀을 이루어 협업에 의해 분석이 되던 상황이 이제는 전문 프로그램(그리고 언어)으로 대체되고 있는 상황이다. 그러면서 데이터 분석에 대한 더 정확히 각 분야에 대한 경계 또한 모호해 지고 있는 상황이다. 그래서 이러한 점을 구분하고자 '데이터 과학'이라는 용어가 사용되기 시작했다고 저자는 말하고 있다. 그러나 이러한 구분 또는 사용이 일관되지 않음은 물론 관련 종사자 자신들의 전문분야(데이터 과학)에 대한 과신을 불러왔다고 한다.


[사진] (위) p.11와 (아래) p.12 에서 이 책에 대해 설명하는 부분
이 책은 그런 모호한 문제들을 좀 더 정확히 구분지어 진짜 '데이터 과학자'로 일하려는 사람들을 위해서 만들었다고 한다. 또한 데이터 분석이 의사결정에 중요한 영향을 미치다 보니 기업이나 MBA 과정 등에서도 별도의 부서나 과정이 개설될 만큼 중요지고 있어 '비즈니스 데이터 분석'에 중점을 두고 각 방법들을 설명하고 있다. 또한, 데이터 분석을 위한 다양한 도구가 사용되다 보니 사진에서 보이는 것처럼 이 책의 목적은 특정 도구에 대한 책이 아닌 데이터 분석 방법 자체에 대한 책임을 강조하고 있다.

[사진] 본 책 p.90~91, 「2. 회귀」 설명 부분
한빛 미디어 책 소개란는 이 책의 난이도를 중고급으로 표기하고 있는데, 고급으로 분류되어야 되지 않나 싶을 정도로 사진에서 보는 것처럼 수식으로 가득하다. 데이터 분석 방법 자체에 대한 설명이 이 책의 핵심이다 보니 머신러닝을 활용을 위한 통계학적 기법에 대한 설명이 가득한데, 수학식에 대한 설명이 너무 없어 데이터 분석에 조금 안다고 덤볐다간 낭패를 볼 것 같다. 그래서 실제 데이터 분석 개발자나 현업에서 실력 업그레이드를 목표로 하는 조금 더 명확히는 통계학에 대해 충분한 지식을 갖춘 분들에게 추천한다. 그렇지 않으면 다양한 방법을 담고는 있지만, 내용이 많이 어렵다 보니 그 내용들 이해하겠다고 또 다른 책들을 찾아서 헤매야 될지도 모르겠다. 또 하나 아쉬운 점은 분석 방법 중간 중간에 삽입된 그래프가 실제 기업의 사례이기는 하지만, 분석 방법 설명에 비해 실제 사례 제시 또한 부족하다는 생각이 든다. 개인적으로는 이 책을 사례 자체 보다는 분석 방법(특히 통계학적 측면에서)을 공부하고 싶은 분들에게 추천한다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
-
비즈니스 의사결정을 위한 통계학과 경제학 등을 통해 데이터를 분석하고 활용하기 위한 인공지능과의 만남을 기술한 책인데요.
핵심 머신러닝 알고리즘까지 실무자를 위한 빅데이터 기술을 다루고 있습니다.
자세한 통계지식 설명, 실제 애플리케이션과 기술, 인사이트를 담고 있어서 데이터 활용을 하는 전문가들에게 유용한 책이라고 할 수 있겠습니다.


-
1. 시작
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
2022년 7월달에 소개할 책은 「비즈니스 데이터 과학」 입니다
<표지>
이책을 한마디로 ‘비즈니스 의사결정을 위한 통계학’이라고 할 수 있습니다.
과학자, 비즈니스 전문가, 엔지니어는 비즈니스 데이터 과학자가 되기 위한 준비를 할 수 있게 도와줍니다.
이책은 기본적으로 어렵습니다.
통계학, 경제학, 인공지능, R까지 어느정도 알고 있는 사람들을 대상으로 쓰여진 책입니다.
2.목적 (책을 쓴 이유)
데이터 과학을 수행하는 방법에 관한 책입니다.
데이터를 사용하여 비즈니스를 운영하는데 도움이 되는 통계, 머신러닝, 경제학에서 나온 핵심 원칙과 모범 사례를 제시합니다.
대상독자는 데이터 과학 기술을 습득하려는 과학자, 비즈니스 전문가, 엔지니어 등입니다.
지금부터 책의 내용을 요약하고 살펴보도록 하겠습니다.
3.책의 내용
이 책은 총 10장으로 구성되어 있습니다.
먼저 1장은 비즈니스의 현실은 복잡하기 때문에 복잡한 상황을 인식하고 분석하기 위해서 불확실성의 개념을 알아야 하며, 확률을 통해서 불확실성 개념을 이해하도록 돕습니다.
<페이지 51>
2장은 회귀 기본 프레임워크와 관련된 용어를, 3장은 고차원 모델링을 위한 주요 기술을 소개합니다.
<페이지 90>
4장은 가장 많이 마주하는 예측 문제인 분류에 대해서 다루고 있습니다.
<페이지 161>
5장부터 ~ 6장까지는 가격 최적화를 위한 반사실적 분석에 대한 핵심 내용을 다루고 있습니다.
<페이지 214>
7장에서는 좋은 결정을 내리는 데 필요한 정보를 포함하도록 고차원 데이터를 저차원으로 압축하는 방법을 다루고 있습니다.
<페이지 298>
표준 데이터 과학 도구를 사용하여 지저분한 비정형 텍스트에 포함된 정보를 활용하고 비즈니스 의사결정에서 텍스트를 데이터로 활용하는 것을 8장에 다루고 있습니다
<페이지 310>
비즈니스 데이터 과학에 성공적으로 적용된 완전 비모수 회귀 방법인 회귀(및 분류) 트리와 포레스트를 9장에서 소개를 합니다.
<페이지 361>
마지막 10장에서는 오늘날의 비즈니스 데이터 과학을 확장하여 이 새로운 머신러닝 기반 인공지능에 대해 생각하기 위한 프레임워크를 설명합니다. 이러한 시스템을 구성하는 요소와 요소 간 결합이 어떻게 이루어지는지 이해하는 것은 인공지능 기술을 기반으로 비즈니스를 구축하려는 사람에게 중요하다고 설명합니다.
<페이지 384>
4. 책을 읽은후
통계학 관련해서 많은 알고리즘을 소개하고 있습니다.
R프로그래밍 언어에 대해서 알고 있어야 하고, 기본적으로 통계학, 경제학을 알고 있는 사람이 읽을 수 있는 난이도가 상당히 높은 책입니다.
데이터 분석가가 되고 싶구나 현재 현업에 있다면 참고할 수 있는 내용이 많을 것입니다.
여기서 책의 서평을 마무리 짓고자 합니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
감사합니다
-
좋은 책입니다.
당연히 대학교 학부에서 사용할 수 있는 책인데, 교수용 자료 요청드립니다.
boklim@knu.ac.kr
김보민 드림
-
이 책은 다양한 데이터 모델링 방법에 대해서 소개하고 있습니다. 회기 모델링, 정규화 등등 데이터를 모델링하는 방법을 소개하고 있습니다. 또한 패턴을 알아내거나 어떤 미래의 값을 예측을 하기 위한 분석방법에 대해서 소개하고 있습니다. 물론 이책을 정독한다고 하더라도
실제 서비스에서 어떤 데이터에서 유의미한 값을 추출해 내기란 여간 어려운일이 아니겠지만, 대략적으로의 개념을 파악하기에는 수박 겉햝기 식이라도 도움이 되리라 생각이 됩니다.
이 책을 읽으면서 이해되는 부분도 있었지만, 앞부분에 수학식과 통계관련 용어들이 많이 등장하여, 조금 당황스러웠습니다. 학창시절 이과임에도 수학을 즐기지 못하여 이과를 선택했던것을 후회하던 옛기억이 떠오를만큼, 책을 읽으면서 썩 기분이 좋지 않았습니다. 뒤부분으로 가면서 아는 용어들이 좀 등장하여 그제서야 나쁜기분이 풀리기는 하였습니다. 빅데이터가 통계와의 연관성이 있음을 다시금 깨닿게 되었고 역시 데이터 사이언티스트의 길은 멀고도 험하다는 것을 다시금 알게해준 책이 아니었나 싶습니다. 그래도 빅데이터 관련 업에 종사하시거나 또는 데이터 사이언티스트를 꿈꾸는 분이 계시다면 정독하시는 것을 추천드립니다.
-
몇년전 빅데이터란 말이 인구에 회자되던 시기가 있었다. 여전히 데이터 홍수의 시대에 살고 있지만 빅데이터란 말은 이제 좀 식상하기도 하고 너무 일반화 됐다고 해야하나? 아무튼 그런 시절이다... 지금은...
어디든 데이터가 넘처나지만 아직까지도 우리가 이 데이터를 잘 활용하고 있는지는 의문이다. 일부 데이터를 이용한 비즈니스에 성공한 기업이나 분야는 있지만 아직까지도 우리 인류 문명은 우리가 생산한 이 엄청난 데이터를 잘 활용하고 있지는 못한 것 같다.
수많은 데이터 중에서 의미있는 무언가를 찾아내는 것은 그만큼 어렵다...
데이터 하면 통계가 먼저 떠오른다... 통계적 분석 기법은 전통적으로 데이터를 분석하는 기술이고 여전히 유효하다... 경제학은 전통적으로 데이터를 수집하고 분석하는 전통적인 분야이고 학문이다, 경제라는 것이 원래 수치 데이터가 많다보니까...
인간의 사고와 인지로 데이터 사이의 의미있는 정보를 추출하고 활용하기에 세상은 너무 빨리 변하고 생산되는 데이터도 어마어마하다... 그렇기에 머신러닝이나 딥러닝과 같은 인공지능을 기반으로 한 분석과 예측이 요즘은 활발하게 이루어지고 있다.
데이터 사이언스 그리고 데이터 사이언티스트가 되기 위해서 효과적인 방법은 그렇게 많지 않은 것 같다... 통계를 비롯한 수학적 지식도 있어야 하고 데이터가 속한 도메인 영역 또는 여러 영역을 아우르는 융합적 지식과 사고도 필요하고 조금 고급지게... 아니 시류에 편성하고자 한다면 인공지능에 대한 지식과 기술도 필요하니... 참 어려운 분야가 아닐 수 없다...
이들을 아우르는 재미난 책이 지난 6월에 출판됐다. "비즈니스 데이터 과학"


데이터 사이언스라고 하는 새로운 분야에 대한 접근방법을 제시하지만 철저히 비즈니스 현장에서 데이터 기반의 의사결정을 위해 필요한 방법들에 대한 내용을 중심으로 다룬다.
이를 위해 통계적 방법뿐만 아니라 빅데이터를 다루기 위한 머신러닝 기법에 대해서도 친절하게 안내하고 있다.
데이터 사이언티스트가 되기 위한 사람들에 초점을 맞춘 책으로 데이터 분석에서의 과학적 접근법을 배우려는 사람들에게 좋은 입문서가 될 것을 생각한다.
많은 수식이 동반되는 책이다 보니 이렇게 기호를 설명하는 친절함도 보여준다.

다만 아쉬운 점은... 수식들에 대한 상세한 설명이 없고... 개인적으로 R이 아닌 파이썬으로 되어있었으면 좋았을것 같다는 생각을 해본다.
※ 본 리뷰는 IT 현업개발자가, 한빛미디어 책을 제공받아 작성한 서평입니다.
-

소개하고자 하는 도서는 통계에 기반하여 머신러닝에 대해서 설명하고자 한다.
일반적으로 데이터 분석 및 머신러닝에 대한 절차 및 과정에 대한 설명을 주요하게 다루는 것이 아닌
머신러닝 내에서 적용되는 skill이 통계적 관점에서 어떻게 해석되어지고 어떠한 이론을 기초로 해서 적용되는지에 대해서 풀어 나간다.
도서 내 실습은 R언어를 통해서 표현되지만, 이해를 돕는 정도이기에 해당 언어를 몰라도 본문 내용 이해에는 큰 지장이 없다.
목차
Chap1. 불확실성
통계는 크게 2가지 관점인 빈도주의와 베이지안주의로써 나뉘어져서 표현될 수 있다.
빈도주의는 확률에 대해서 객관적으로 해석함으로써, 관찰된 데이터와 관찰되지 않은 데이터들에 의한 우도에 의존한다.
베이지안 주의는 빈도주의와 반대로 주관적 해석함과 더불어서 조건부 확률에 대한 개념을 활용한다.
Chap2. 회귀
어떠한 x값을 토대로 y값을 유추함을 말하는 개념으로써,
이때, x는 입력변수, y는 반응변수라 말할 수 있다.
이 수식을 설계하는 방법에 대해서 이번 장에서 설명한다.
Chap3. 정규화
흔히 머신러닝 내 정규화는 데이터의 분포를 일정하게 변환 함을 말한다.
이를 통계적 관점에서 표본내 편차와 표본외 편차라는 두 관점에서 왜 정규화를 해야 하는가,
또한 어떠한 방법으로 정규화하는지를 이번 장에서 설명한다.
Chap4. 분류
분류는 label 이 존재하는 지도학습 분류와 label 이 존재하지 않는 비지도 학습 분류로 나뉜다.
위 두 분류에서 확률적으로 어떻한 방법들을 사용해서 분류하며 이에 소요되는 비용에 대해서 서술한다.
또한, 병렬처리는 통해서 얻을 수 있는 이점에 대해서 설명한다.
Chap5. 실험
일반적인 실험의 경우는 설계한 분류, 회귀 모델들을 어떠한 방식으로 학습 시킬 것인가에 대한 설명일 것이다.
이번 장에서 말하고 싶은 것은 앞서 설계한 모델을 어떠한 통계적인 기법으로써, 옳은가 또는 옳지 않은가에 대해서
증명하는지에 대한 방법론을 제시한다.
Chap6. 제어
앞 장에 실험은 완전 무작위 AB실험, 유사 실험 설계, 도구 변수 변수 시나리오 구성된다.
위 3가지 방법으로 실험을 진행하여도 결과가 원하는 방향으로 나오지 않을 수 있다.
이는 모든 요인를 관찰하는 것은 불가능하며, 이 결과를 신뢰 할 수 있도록 충분히 주요 요인이 제어 됫을거라는
기대, 추정이 필요하고 이러한 가정을 조건부 무시가능성의 가정이라고 말한다.
이에 대한 설명을 이번장에서 한다.
Chap7. 인수분해
일반적인 머신러닝에서는 차원축소라는 표현이 더 익숙하다.
차원 축소가 이루어 질 때, 통계적 관점에 대한 설명을 이번장에서 한다.
Chap8. 데이터로써의 텍스트
텍스트를 데이터로 사용하기위한 과정을 이번장에서 설명한다.
Chap9. 비모수
앞서 설명했던 장들은 모수로써, 입력이 반응에 영향을 미치는 방법에 제한을 둠을 말한다.
이는 결국 paramter 최적화를 통해서 데이처에 모델 적합함을 의미한다.
비모수라 함은 데이터 관촬을 통해서, 트리 및 포레스트 기반한 분류를 말하며,
이에 대해서 이번장에서 설명한다.
Chap10. 인공지능
인공지능이라 함은 도메인 구조(비지니스 룰) + 데이터 생성 + 범용적 모델(ML, DL) 결합을 통해서 만들어 진다.
이에 대해서 이번장에서 설명한다.
정리
기존 데이터 분석에 대한 도서들의 방향성이 머신러닝에 대한 일반론적인 접근으로 풀어서 나아갔다면,
본 도서는 머신러닝에서 사용되는 수많은 skill이 통계적 관점에서 왜 쓰여졌는지에 대한 좀더 인사이트를 가질 수 있도록
풀어서 설명하고 있다.
물론, 통계에 익숙하지 않은 독자들이 더 많을 것이며, 본인 또한 그렇다.
그렇지만, 더 나은 데이터 과학자가 되기 위해서 배워야하는 기초지식으로는 의심치 않는다.
- 한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
-
한줄 서평
도대체 데이터 분석을 실무에 어떻게 적용하는 지 궁금하다면? 꼭 읽어볼 것!
학습 후기
저자 github에 제공된 노트북파일을 따라가면서 읽기 좋은 책이었다. 필자는 파이썬을 주언어로 사용한 지 오래되어, 학부때 사용했던 R은 오랜만이었지만 분석의 흐름을 이해하는 데 어려움은 없었다.

특정 분야에서 모델링을 어떻게 시작해야하고 어떤 값 혹은 결과를 바탕으로 분석 방향성을 잡아야할 지 가이드가 되는 알찬 내용의 책이었다.
특히 어떠한 경우에 변수를 승법적으로 변하도록 모델링을 해야하는 지, 변수 선택 방법론의 장단점과 같은 기초적인 모델링 지식부터, 모델 파라미터에 대한 불확실성을 어떻게 핸들링해야하는 지와 같은 중급자에게 요하는 지식까지 다양한 데이터와 분석 예제를 통해서 설명하고 있다는 점이 도움이 되었다.

브랜드별 가격 탄력성을 통해 소비자의 특성을 파악해 광고 마케팅에 활용하는 예시와 같이 분석 결과를 의사결정에 반영하는 방향성과 분석 결과 해석에 있어 주의해야할 점과 같은 실무자에게 필요한 내용들을 담고 있다.
개인적으로 금융 분석 프로젝트를 자유주제로 진행하게 된 시점에 중급자 수준의 좋은 가이드를 제공받아 만족스러웠다.
-
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=296868256
비즈니스 데이터 과학
비즈니스 분야에서 자주 언급되는 문제와 관련된 통계학, 경제학 개념 및 빅데이터 기술을 소개한다. 이 책에는 아마존과 마이크로소프트에서 데이터 과학팀을 이끌고 시카고 대학교에서 계량
www.aladin.co.kr

책의 표지
01. Summary

책의 뒷면
이 책은 학문적이며, 실용적이다. 각각의 챕터를 통해 문제를 풀기 위한 고민, 분석한 결과에 대한 해석, 이러한 해석을 기반으로 보완할 수 있는 방법을 제시하고, 그 결과와 성능을 보인다.
R을 베이스로 한다. 전체적으로 문제에 대한 소개 > 관련 이론과 논문에 대한 설명 > 통계학적 분석과 해석 > R 코드를 통한 실행과 추가적인 분석을 바탕으로 한다. 적어도 R 코드를 읽을 수 있는 수준은 되어야 이 책의 내용을 더욱 유용하게 읽을 수 있다.
02. Targets

책에 대한 설명
적어도 데이터에 대한 공부와 실력이 어느정도 있어야 한다.
데이터 분석가 혹은 대학원을 염두에 두고 있다면 강력히 추천하며, 데이터를 이용해 문제를 풀고자 하는 관련 실무자들에게도 아주 유용할 것으로 보인다.
03. Review

본 내용이 시작되기에 앞서 이후 사용될 표기법에 대한 정리
아마 이 책으로 하여금 근 몇 년 동안 파이썬이나 R 등의 프로그래밍 언어, 머신러닝, 수학, 통계학 등에 대해 단편적으로만 제시될뿐 이것들을 하나로 엮는 컨텐츠가 없어 힘들어하던 많은 데이터 계열 입문자들에게 좋은 답안이지 않을까 싶다.
가장 큰 장점은 통계학, 수학 등에 대해 초보적인 수준이더라도 이 책을 통해 스스로 수준을 높여갈 수 있을 것으로 보인다는 것!
(만약 이 사실이 의심된다면 이 책을 중간 정도부터 읽어보고, 마음껏 어려워한 뒤 다시 처음부터 읽어봄으로써 진실임을 깨달을 수 있을 것이다)
구성은 이전에도 말했듯 문제를 제시하고, 이를 풀어나가는 과정에서 이론적인 밑바탕, 수리통계학적 설명, 코드를 통한 문제풀이와 이에 대한 해석에 이르기까지 실제 그러한 문제를 풀어보는 입장에 스스로를 대입해 읽어나가다보면 꽤나 재밌게 읽을 수 있었다.
이번달에 시간이 도저히 안나 한 번밖에 읽지 못했던 것이 아쉬울 정도이며, 추후 몇 번의 반복독서를 통해 보다 친숙해지면 좋을 도서
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
-

"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
"하지만 비즈니스 문제에 대한 더 깊은 분석을 위해서는 무슨 일이 일어났는지보다 왜 이런 일이 발생했는지를 파악해야 한다."
이래저래 데이터 과학이 화두입니다. 책 뿐만 아니라 온/오프라인 강의에도 데이터 분석을 가르치는 강의가 많아졌고요. 하지만 '데이터 분석'이 붙어있는 책이나 강의를 보면 파이썬 코딩 방법이나 머신러닝/딥러닝 정도를 가르쳐 주는 것이 대부분입니다. 실제 현장에서는 모델 구현이나 해당 모델의 결과값도 중요하지만 그 결과로부터 어떤 인사이트를 이끌어 낼 수 있는지도 중요한데 말이지요. 아무래도 후자의 내용을 다루는 곳은 많이 없는 것 같다는 느낌입니다.
다시 말해, 예측(Prediction)과 추론(Inference) 모두 중요한데 시중에는 전자에만 방점을 두는 책이나 강의가 많은 듯합니다. 그래도 최근에는 추론을 통해 프로덕트를 분석하고 이를 비즈니스에 적용하기 위한 움직임도 늘어나고 있는데요. 이에 따라 후자와 관련된 책 역시 하나 둘 나오고 있습니다. 그리고 이 책 역시 그런 흐름에 발맞춰 나온 책이라고 할 수 있겠고요.
회귀, 정규화, 분류 등 책의 전반적인 흐름은 기존의 서적과 유사합니다. 하지만 더 자세히 들여다보면 책의 특징이 보이는 곳이 많은데요. 기초만을 다루는 기존의 책과 달리 어떻게 하면 결과값을 더 자세히 해석하고 신뢰도 있게 바라볼 수 있을 지에 대해 여러가지 방법론을 제시하고 있습니다.
개인적으로 재밌게 읽었던 부분은 Chap 5, 6 에 걸쳐져 있는 '실험'과 '제어'에 대한 내용이었습니다. 실제 데이터 분석을 하면서 실험 설계가 되었는지 혹은 어떤 조건을 제외 혹은 포함해야 할 지에 대해 고민한 적이 있는데요. 그에 대한 힌트를 얻고 당시 어떤 생각을 했는지에 대해 반추해 볼 수 있어서 좋았습니다.
책의 내용은 좋지만 몇 가지 주의사항 역시 있습니다. 일단은 그리 가벼운 책은 아니라는 점인데요. 서문에서도 말하고 있는 것처럼 경제학에 대한 개념이 있어야 이해가 쉬운 부분도 있고, 수학 기호도 꽤 있어 이런 부분까지 모두 이해하고자 한다면 기초 수학에 대한 베이스가 있어야 하는 것도 사실입니다. 그리고 일련의 R 코드를 보고 이해하기에 문제가 없을 정도가 되어야 책을 보는데 문제가 없을 것 같습니다.
R 코드를 어느 정도 볼 수 있고, 기초 수학 지식이 있는 실무자가 실제 데이터 분석 과정에서 자신이 잘 하고 있는지 혹은 어떻게 하면 더 잘 할 수 있을 지를 고민중이라면 해당 책은 그에 대한 좋은 가이드가 되어 줄 것으로 생각됩니다.
-
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."


R로 실습하는 책입니다.
비즈니스에서 다루는 다양한 데이터셋을 이용해서 통계 알고리즘에 대한 것을 공부할 수 있습니다. 인공지능에 대한 것은 마지막 챕터에서 조금 다루긴 합니다. 실습보다는 이론에 대한 내용이 많습니다. 수식도 많이 있어서, 통계학과 미적분학에 대한 대학교에서 기초적인 수준을 공부했다면 좀 더 보기 좋을 것 같습니다.

데이터를 여러 가지 알고리즘을 적용해서 통계적인 분석을 한 뒤, 이에 대한 결과값들을 해석하는 책입니다. 여기에 나온 수식들을 제대로 이해못한다면 이 책에서 스킵해야 하는 부분들이 상당할 것으로 보입니다. 통계학에 기초를 어느정도 공부한 사람들이 보면 좋을 책으로 보입니다.
대학에서 다룰만한 교재라는 느낌이 강합니다. 그래도 저자가 아마존에서 오래 일한 사람이기에 글로벌한 데이터를 다룹니다. 데이터 분석가를 꿈꾸거나, 다양한 데이터를 핸들링해서 데이터를 여러 가지로 통계 분석을 하고 싶다면 이 책은 꽤나 흥미로울 것입니다.
-
[도서 소개]
더 나은 의사결정을 위한 필수 통계학, 경제학 개념부터 핵심 머신러닝 알고리즘까지
실무자를 위한 비즈니스 빅데이터 기술
비즈니스 분야에서 자주 언급되는 문제와 관련된 통계학, 경제학 개념 및 빅데이터 기술을 소개합니다. 이 책에는 아마존과 마이크로소프트에서 데이터 과학팀을 이끌고 시카고 대학교에서 계량경제학 및 통계학 교수로 재직하면서 데이터 과학 커리큘럼을 개발한 저자의 경험이 고스란히 담겨있습니다. 통계학, 경제학 개념부터 머신러닝 알고리즘까지 실무자가 알아야 하는 필수적인 내용들을 친절하게 설명하며 이를 R 프로그래밍 언어로 직접 구현하면서 모델링 기법의 목적과 사용법을 더 자세히 이해할 수 있게 돕습니다. 데이터 과학자, 데이터 엔지니어, 인공지능 개발자, 비즈니스 의사결정자 그리고 고급 통계학 지식을 얻고자 하는 사람에게 유용한 책입니다.
[대상 독자]
- 기업과 상품의 가치를 올리고 싶은 사람
- 고객을 더 잘 이해하고 싶은 사람
- 고급 통계학 지식이 필요한 사람
[주요 내용]
- 비즈니스 의사결정에 필요한 통계학, 경제학 이론과 머신러닝 알고리즘
- 텍스트 분석, 가격 결정 및 수요 추정, A/B 실험, 고객 행동 분석의 사례
- 머신러닝 도구를 사용하여 비즈니스 의사결정을 내리는 방법
- 인공지능으로 비즈니스 문제를 해결하는 방법
[서평]
아마존 수석 이코노미스트(부사장)의 노하우와 사례로 가득한 실무 중심의 비즈니스 데이터 과학
오늘날에는 머신러닝과 통계학, 데이터 기반의 사회과학 및 경제학과 같은 분야에서 끊임없는 지적 융합이 일어나고 있으며, 이러한 융합은 데이터 분석의 질을 높여줍니다.이 책은 최선의 데이터 분석 방법을 설명하기 위해 머신러닝과 통계학 그리고 경제학을 융합합니다. 머신러닝과 통계학으로 자동화 및 확장 방법을 배우고, 경제학에서 인과관계 및 구조 모델링을 위한 도구를 가져오며, 이러한 방법들이 비즈니스 의사결정과 어떤 관련이 있는지 설명합니다. ‘무슨’ 일이 일어났는지가 아니라 ‘왜’ 이런 일이 발생했는지에 초점을 맞추어 설명하기 때문에 다양한 모델의 핵심 개념을 쉽게 이해할 수 있습니다. 저자가 학생들을 가르치며 얻은 노하우와 이베이, 마이크로소프트, 아마존에서 경험한 사례를 여러분의 실무에 적용해보세요!
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
-
널리 알려진 데이터 과학 알고리즘들의 “왜, 무엇”에 초점을 맞추는 책으로, 다양한 실무 예제와 질문 및 개선 시도 등의 독특한 접근법으로 학습할 수 있다는 점이 일품이다.
그동안 데이터 과학이라 불리는 넓은 범위의 책을 제법 많이 읽어왔다고 생각했는데 이 책에는 그동안 다른 책에서 볼 수 없던 새로운 개념과 인사이트들이 담겨있었다.
보통 Python, R의 코딩 중심 책이거나, Pytorch나 Tensorflow와 같은 프레임워크를 활용하는 법이나, 주어진 예제의 성격에 따라 일반적인 패턴을 배우거나, 수학 중심의 이론을 살피거나, 기본 알고리즘을 배우는 책 정도로 분류할 수 있겠다.
그렇기에 대부분 마치 정해진 것처럼 당연히 그래야 하는 것 처럼 의문을 가지지않고 비슷한 예제를 참조해가며 모델링하고 왜 이 모델은 정규화를 적용해도 적용하지 않아도 비슷한 성능이 나오는지 등 제대로 이해하지 못한 채 넘어가는 스킬만 쌓여왔다.
제대로 된 모델링은 위해서는 주어진 데이터의 질감을 제대로 느끼고 데이터들의 상호 관계를 파악하며 세간에 알려진 기법을 적용하기에 어떤 무리나 한계점이 있는지 파악할 줄 알아야 한다.
그런 문제를 해결할 줄 알아야 뛰어난 예측 성능을 자랑하거나 변화하는 데이터에 유연하게 적응할 수 있는 모델을 설계할 수 있을 것이다.
그럼에도 풍부한 경험이 부족한 것은 차치하더라도 늘 그렇듯 써오던 모델이나 알고리즘을 정확하게제대로이해하지 못하니 설계할 때마다 어디서부터 시작해야 할지 막막했던 경험이 잦았는데 그럴때마다 이제 비벼볼만한 희망을 얻게 된 것은 이 책 덕분이라고 할 수 있다.
즉, 다른 책들이 “어떻게”에 초점을 맞춰왔다면 이 책은"왜", "무엇"에 초점을 맞춘다고 정리해 볼 수 있다.
각 데이터의 상황이 어떤지 알고리즘의 한계가 무엇인지 명확하게 이해하고 있다면 모델을 설계하는데 적시적소 적절한 도구를 활용할 수 있음은 물론 예측과 다른 결과가 나왔을 때 문제 해결 방법이 무엇인지 감을 잡을 수 있다. 이 책은 그런 근원적인 내공을 쌓는데 많은 도움을 준다.
도입부인 “CHAPTER 0 들어가며”부터 첫인상이 범상치 않았다. 다음은 시간의 흐름에 따른 개별 주식 종목들의 수익률 분포도로 평균도 표기되어 있다.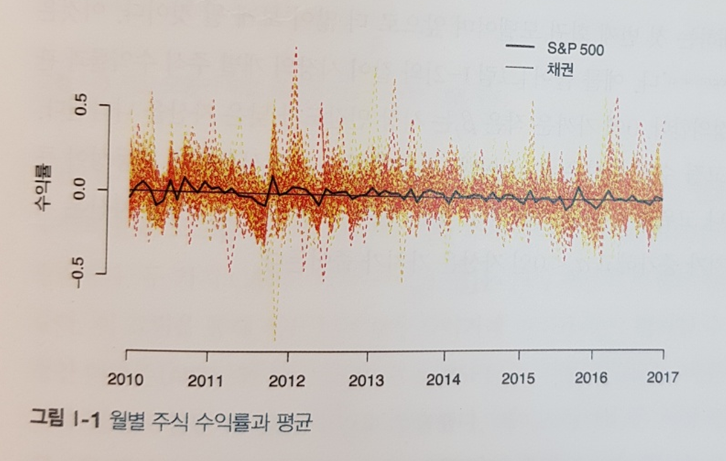
유용한 정보이지만 특정 기간이왜 더 불안정하게 수익률이 분산하는지, 언제 다시 발생할지에 관련된 답은 구할 수가 없다.
데이터로부터 원하는 것을 얻는 과정이 결코 쉽지 않음을 보여주는 현실에서 자주 맞닥드리는 문제로 포문을 여니 호기심이 샘솟았다.
데이터 과학의 큰 축 중 하나가 업무 도메인인만큼 여기서 전통적으로 오래 사용된 모델을 하나 들고 온다.CAPM이라는 모델인데 데이터 개별 주식 수익률을 시장 평균과 연결하는 모델이다.
아래 첫번째 그림은 CAPM의 산점도 인데 이것만으로는 직관적인 의사결정이 어렵다.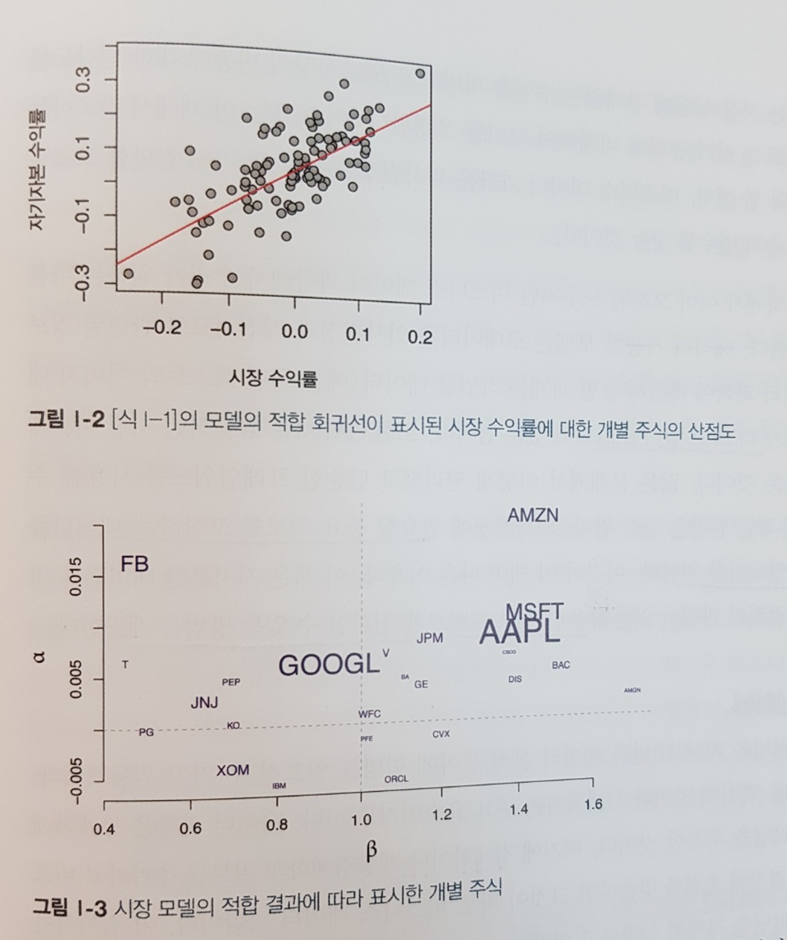
두번째 그림은 의사결정에 중요한 정보를 저차원 공간에 투영한 결과이다. 즉, 전체 원칙이나 모델을 훼손하지 않으면서도 의사결정을 가능하게 하는소수의 변수를 찾는 과정이 소개되고 있고 그것이 이 책이 나온 이유라 설명하고 있다.
이즈음부터 이 책은 뭔가 다르구나라는 생각으로 정신없이 읽게 되었다. 물론 그림I-3이 나오기 위해 알파, 베타값이 어떤 의미를 담고 있는지 더 나아가 활용해볼만한 것이겠구나 느낄 수 있는 안목이 필요할 것이다.
다만 이를 위해서는 앞서 설명한 바와 같이 세간에 널리 알려진 뻔한 알고리즘이나 방법론들의 “왜”, “무엇”에 초점을 맞춰 학습할 필요가 있다. 뒷부분에 이어지는 내용들은 “왜”, “무엇”에 초점을 맞출 수 있는 학습을 도와준다.
일례로 부트스트랩의 주제도 다른 책에서 활용 방법이나 효과만 얻었던 반면 이 책에서는 중심극한정리와 비교하며 설명한다.
둘을 비교해가며부트스트랩이 고전 공식으로 설명 불가능한 변수 선택, 계산 근사에 적용할 수 있다는 점이나 파라미터 수가 데이터 수보다 많을 때 적용하기 용이하다는 점 등을 알 수 있었다.
예제를 통해 리샘플링해가며 R언어를 코딩해가는 과정에서 데이터의 질감을 느끼며 이에 종속된 각 알고리즘들이 어떻게 변화하고 작동하는지 느낄 수 있다는 점이 신기했다.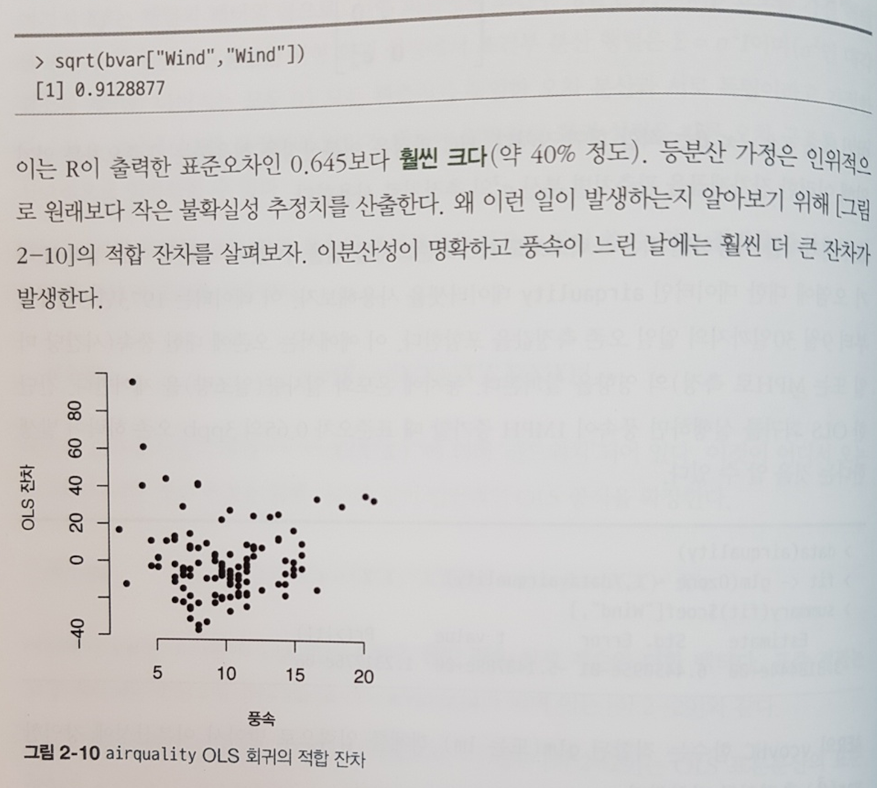
실제 왜 그런지 느끼고 이해하는 과정을 통해 고전 모델이나 부트스트랩의 장, 단점을 명확하게 파악하게 되기 떄문에 다른 모델을 설계하거나 문제점을 보완할 때 적절히 활용할 수 있게 되는 것이다.
단순히 이에 그치지 않고 새로운 과제를 자꾸 던져주는 점이 매력적이다. 부트스트랩으로 설명을 계속 이어가자면 추정량이 편향될 염려가 있을 때 신뢰구간을 고려한 더 복잡한 알고리즘을 적용해 볼 수 있음을 보여준다. 각 상황에 맞게 문제 해결 능력을 키울 수 있는유연성을 키울 수 있게 도와준다.
뻔히 알고있는 줄로만 알았던 개념들을새로운 각도로 정의하는 것 또한 신기했다. 몇년 동안 수도 없이 돌렸던 회귀의 개념이 새롭게 보이기 시작했다. 같은 사물이라도 여러 각도로 보면 더 이해도가 늘어나는 법이다.
회귀를 x에 대한 y의 조건부 확룔분포라고 정의한 책은 거의 보지 못한 것 같다. 달리 생각하면 당연한 말인가 싶으면서도 이런 사고나 접근법 덕분에 모델 설계에서 반짝이는 아이디어의 또 다른 진입로를 얻을 수 있다 생각한다.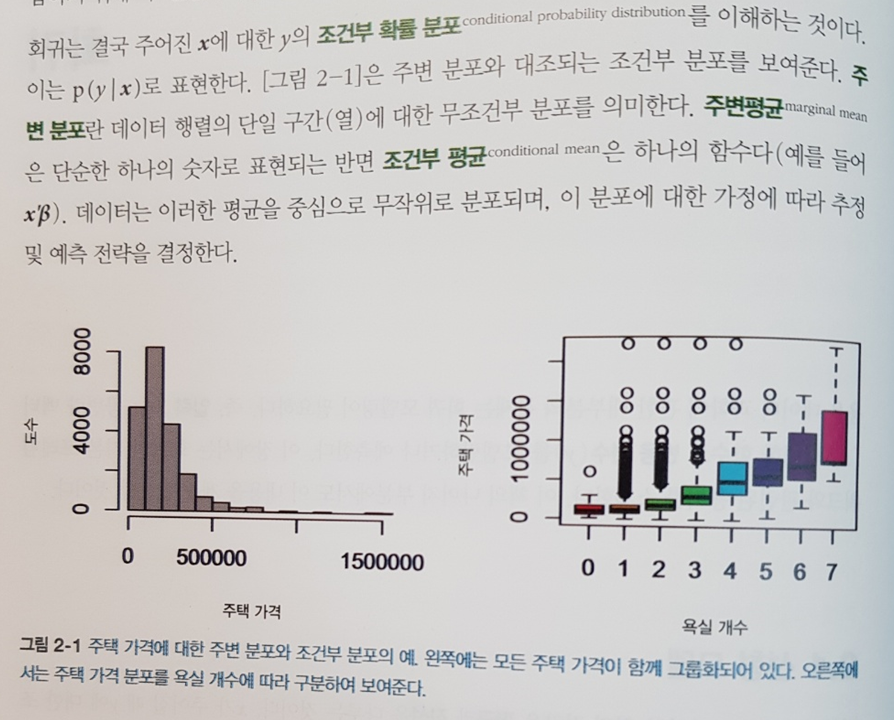
개인적으로는 CHAPTER 5 실험 파트와 CHAPTER 6 제어 파트가 가장 마음에 들었던 부분이다. 그동안의 실무 궁금증을 상당부분 해소할 수 있었다.고수에게 어깨너머로 혹은 간신히 사정해서 배울 수 있었던 스킬들이 상당히 많이 담겨있다.
고차원 교란 조정 스킬을 설명하는 하트가 그런 예이다. 간간히 통계 전문가가 아니더라도 설명하기 쉬운 기법이나 팁도 얻을 수 있다.
데이터를 기반으로 끊임없이질문을 던지는 저술방식도 마음에 든다. PCA를 직관적으로 이해하는데 이만한 예를 찾기 어렵다.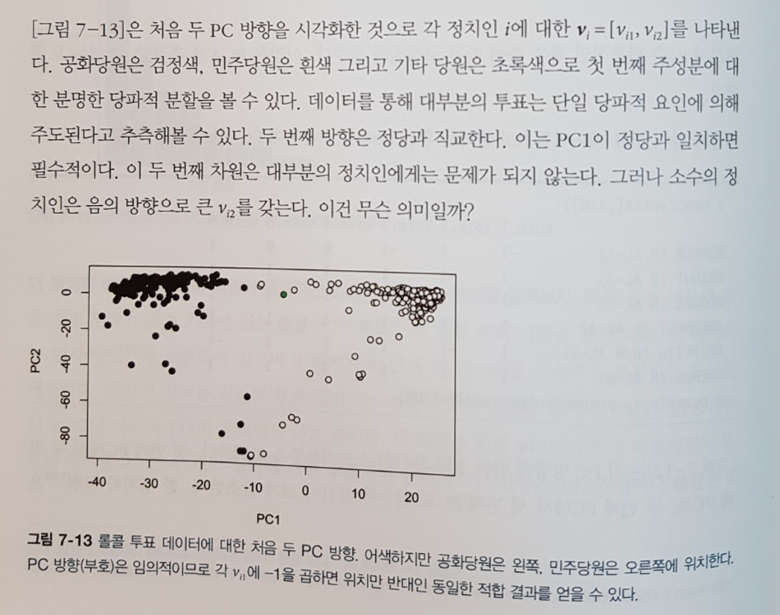
통계학 교수로서의 탄탄한 이론과 전달력, 아마존 부사장이 되기까지의 실무 경험이라는 든든한 양대산맥이 아니면 이런 직관적인 질문과 알고리즘의 논리적 비약과 전개, 적절한 예제 선택 및 활용, 실무적인 관점에서 필요한 만큼의 이론 전달 등이 결코 쉽지 않을것이다.
예제 언어로는 R을 활용한다. 개인적으로는 Python이 마음에 들지만 이 책에 적합한 언어는 확실히 R이다. 범용 언어가 아닌 만큼 확실히 Python의 예열 과정이 없이 코드가 짧고 직관적이다. 책이 전달하고자 하는 개념을 빠르게 실습하며 이해할 수 있을거라 본다.
책 제목의 비즈니스는 무시하면 될 것 같다. 어느 데이터 과학분야에서도 큰 도움이 될만한 책이다.
데이터 과학이라는 용어에서 과학이라는 용어가 왜 끼어들었는지 실감나게 해주는 책이다. 그동안 당연히 그렇게 하라고 해서 그대로 따라하다 데이터 과학 분야의 영혼없는 껍데기가 된 느낌이라면 꼭 이 책을 읽어볼 것을 추천한다.
-
빅데이터와 머신러닝에 대해서는 이미 10여년전부터 미래 트렌드로 각광을 받아왔던 터라서 단어와 분야에 대해서는 낮설지 않고 오히려 익숙해진 것 같다. 과거 빈도주의 통계학과 데이터웨어하우스, 데이터마이닝에 베이지안 통계학 정도 붙여놓은 것처럼 여겨졌는데 이게 시간이 갈 수록 하드웨어의 발전과 초고속인터넷, 모바일 환경에 익숙해지면서 모든 것이 이커머스, 소셜네트워크를 활용한 플랫폼을 의사소통 및 모든 정보, 물류, 문화적인 것까지 빅데이터, 머신러닝은 생활의 일부를 너머 전부까지 노리는 분야가 되었다.
이책의 부제처럼 데이터 과학은 통계학, 경제학, 인공지능의 통합을 통해 모든 비즈니스를 연결지으려고 하고 있다. 요즘 주식시장에 거의 모든 국민들이 관심을 갖는데 거기서도 퀀트 데이터를 활용화하고 사람들은 가공된 데이터로 주가를 설명하고 예측한다. 이책은 이러한 분야에서 쓰이는 빅데이터 기술들을 설명하고 개인에서부터 기업체에 이르기까지 의사결정의 중요한 매개로 데이터 과학을 잘 소개해주고 있다. 첫 챕터는 빈도주의 통계학과 이에따른 가설검정에서의 주의점을 이야기해주고 대안인 베이지언 추론에 대해서 이야기해준다. 두번째 챕터에서는 회귀분석 및 로지스틱 회귀분석에 대해 심도 깊게 설명해준다.
챕터를 거듭할수록 전문가인 저자만의 강력한 노하우를 잘 제시해주고 있으며 풍부한 그래프와 수식으로 이해를 잘 이끌어주고 있다. 또한 실습 데이터를 통해 실제로 설명하는 이론들이 어떻게 구체화되는지 잘 알려준다.
통계와 빅데이터에 대한 관심과 이해도가 있는 사람에게 아주 적절한 책인 것 같다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다." -
달마다 그렇듯 한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받았습니다.
이것저것 내가 관심있는 분야만 공부하는것도 좋은데, 수행평가 라던지, 실제적으로 쓸모있는 알고리즘이나 기법들을 공부해두면 좋을 것 같다는 생각이 들어서, 이번 서평목록에 저번에 신청안한 알고리즘 관련 책이 있으면 좋겠다고 생각했는데, 그런건 없었고, 그래서 목록에서 가장 비슷한 맥락을 다루는 이 책을 읽게 되었다.
책에 따르면, 이 책의 대상 독자는 고학 기술을 습득하려는 과학자, 비즈니스 전문가, 엔지니어 등 이전까지 존재하지 않던 데이터 과학이라는 새로운 분야에 진입하기 위한 다른 영역의 종사자들이다.
다시 한 번 책에 따르면, 비즈니스 데이터 분석은 지난 10년간 스프레드시트와 피벗 테이블에서 R, 스칼라, 파이썬등의 스크립트 언어로 대체되는 혼란한 시기이며, 여러 비즈니스 분석가의 작업이 응용과학자와 소프트웨어 엔지니어의 자동화로 바뀌고 있다고 한다.
그러니까, 새로운 방식의 도래로 인해 기술이 발전하고, 사회가 발전하고, 직업이 생겨나지만 사라지는 혼란속에서 적응하고 살아남고, 이전 방식에만 머물다 도태되지 않기위해 새로운 것을 배워 새로운 분야로 진출하려는 사람들을 위한 책이다.
하지만 그렇다고, 엄청 새롭고 신비로운 내용만으로 가득 차 있지 않다.
새로 출시한 휴대폰이 여전히 CPU, RAM, 디스플레이, 카메라 등으로 구성되어 있듯, 데이터 과학이라는 분야 역시 기존의 여러 분야가 모여 탄생한 분야이기 때문이다.
그래서 누군가는 분명 공부해보거나, 들어봤을 베이지안 추론이라던지, 선형, 로지스틱 회귀, 정규화에 관한 것들과 K-최근접 이웃, 평균, 의사결정 트리, PCA, 그리고 최종장에는 누군가에게는 새로운 발전을 위한 도구이자, 누군가에게는 두려움의 존재인 인공지능에 관해 설명한다.
다 나에게는 다 앞으로 더 자주보고, 공부해야 할 대상들이다.
서평때 마다 대부분 인공지능 관련 도서만 신청하고, 주로 찾고 관심갖는 것도 인공지능에만 치우치다보니, 결국은 이 분야를 더 파고들수록 인공지능이라는 분야를 탄생하게 한 성간먼지와 같은 통계학이나 각종 데이터 처리, 알고리즘에 대한 기본적인 배경지식이 부족한 것이 느껴졌다.
아직 이 책에서 완전히 이해하지 못한 부분들을 다시 훑어보고 기초를 다져야겠다. -
전문가 & 실무자에겐 최고의 레퍼런스가 될 수 있는 책
풍부한 수식과 그래프, 실습 자료가 장점
하지만, 주제가 주제이다 보니 수학적 지식과 R 프로그래밍에 대한 선수 지식이 요구됨
-
이책은 R을 기반으로 작성되었으나, R을 소개하는 것은 아니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
더 나은 의사결정을 위한 필수 통계학, 경제학 개념부터 핵심 머신러닝 알고리즘까지
실무자를 위한 비즈니스 빅데이터 기술
이책은 비즈니스 분야에서 자주 언급되는 문제와 관련된 통계학, 경제학 개념 및 빅데이터 기술 관련 내용을 소개한다.아마존과 마이크로소프트에서 데이터 과학팀을 이끌고 시카고 대학교에서 계량경제학 및 통계학 교수로 재직하면서 데이터 과학 커리큘럼을 개발한 저자의 경험이 담겨 있다. 통계학, 경제학 개념부터 머신러닝 알고리즘까지 실무자가 알아야 하는 필수적인 내용들을 친절하게 설명하며 이를 R 프로그래밍 언어로 직접 구현하면서 모델링 기법의 목적과 사용법을 더 자세히 이해할 수 있게 돕는다.데이터 과학자, 데이터 엔지니어, 인공지능 개발자, 비즈니스 의사결정자 그리고 고급 통계학 지식을 얻고자 하는 사람에게 유용한 책이다.

주요내용은
1.통계학, 경제학, 머신러닝 알고리즘 - 비즈니스 의사결정에 필요한 이론 설명
2.다양한 사례 탐구 - 텍스트 분석, 가격 결정과 수요 추정, A/B 실험, 고객 행동 분석
3.비즈니스 의사결정 방법 - 머신러닝을 사용한 의사결정 방법 제시
4.비즈니스 문제 해결 - 인공지능으로 비즈니스 문제를 해결하는 방법 탐구
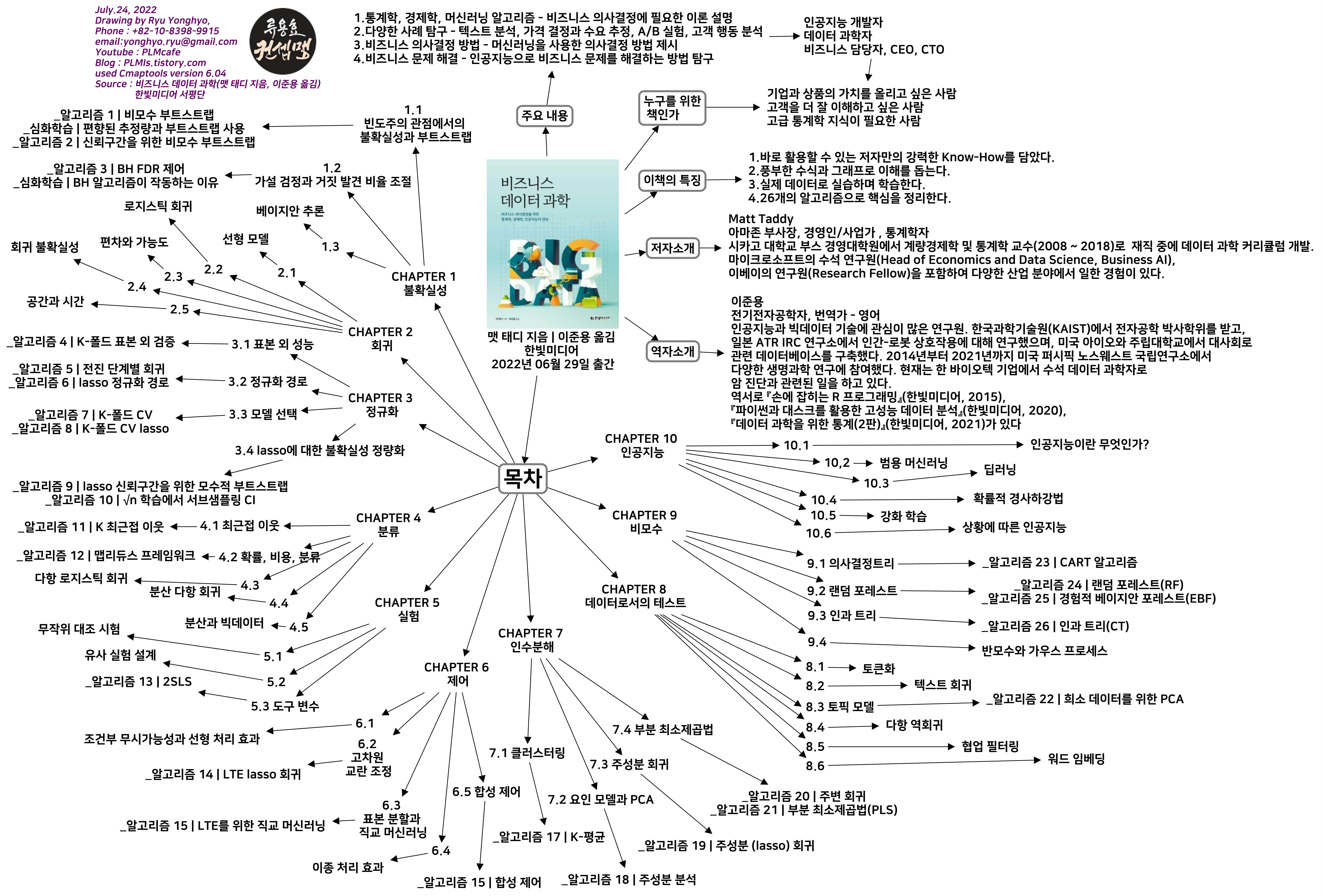
비즈니스 데이터 과학 맵 (맷태지 지음), Map by 류용효
누구를 위한 책인가
기업과 상품의 가치를 올리고 싶은 사람
고객을 더 잘 이해하고 싶은 사람
고급 통계학 지식이 필요한 사람
인공지능 개발자
데이터 과학자
비즈니스 담당자, CEO, CTO
이 책의 특징은
1.바로 활용할 수 있는 저자만의 강력한 Know-How를 담았다.
2.풍부한 수식과 그래프로 이해를 돕는다.
3.실제 데이터로 실습하며 학습한다.
4.26개의 알고리즘으로 핵심을 정리한다.
저자 소개
Matt Taddy
아마존 부사장, 경영인/사업가 , 통계학자
시카고 대학교 부스 경영대학원에서 계량경제학 및 통계학 교수(2008 ~ 2018)로 재직 중에 데이터 과학 커리큘럼 개발.
마이크로소프트의 수석 연구원(Head of Economics and Data Science, Business AI)
이베이의 연구원(Research Fellow)을 포함하여 다양한 산업 분야에서 일한 경험이 있다.
역자 : 이준용
전기전자공학자, 번역가 - 영어
인공지능과 빅데이터 기술에 관심이 많은 연구원. 한국과학기술원(KAIST)에서 전자공학 박사학위를 받고, 일본 ATR IRC 연구소에서 인간-로봇 상호작용에 대해 연구했으며, 미국 아이오와 주립대학교에서 대사회로 관련 데이터베이스를 구축했다. 2014년부터 2021년까지 미국 퍼시픽 노스웨스트 국립연구소에서 다양한 생명과학 연구에 참여했다. 현재는 한 바이오텍 기업에서 수석 데이터 과학자로 암 진단과 관련된 일을 하고 있다. 역서로 『손에 잡히는 R 프로그래밍』(한빛미디어, 2015), 『파이썬과 대스크를 활용한 고성능 데이터 분석』(한빛미디어, 2020), 『데이터 과학을 위한 통계(2판)』(한빛미디어, 2021)가 있다
주요 목차
CHAPTER 1 불확실성
1.1 빈도주의 관점에서의 불확실성과 부트스트랩
_알고리즘 1 | 비모수 부트스트랩
_심화학습 | 편향된 추정량과 부트스트랩 사용
_알고리즘 2 | 신뢰구간을 위한 비모수 부트스트랩
1.2 가설 검정과 거짓 발견 비율 조절
_알고리즘 3 | BH FDR 제어
_심화학습 | BH 알고리즘이 작동하는 이유
1.3 베이지안 추론
CHAPTER 2 회귀
2.1 선형 모델
2.2 로지스틱 회귀
2.3 편차와 가능도
2.4 회귀 불확실성
2.5 공간과 시간
CHAPTER 3 정규화
3.1 표본 외 성능
_알고리즘 4 | K-폴드 표본 외 검증
3.2 정규화 경로
_알고리즘 5 | 전진 단계별 회귀
_알고리즘 6 | lasso 정규화 경로
3.3 모델 선택
_알고리즘 7 | K-폴드 CV
_알고리즘 8 | K-폴드 CV lasso
3.4 lasso에 대한 불확실성 정량화
_알고리즘 9 | lasso 신뢰구간을 위한 모수적 부트스트랩
_알고리즘 10 | √n 학습에서 서브샘플링 CI
CHAPTER 4 분류
4.1 최근접 이웃
_알고리즘 11 | K 최근접 이웃
4.2 확률, 비용, 분류
_알고리즘 12 | 맵리듀스 프레임워크
4.3 다항 로지스틱 회귀
4.4 분산 다항 회귀
4.5 분산과 빅데이터
CHAPTER 5 실험
5.1 무작위 대조 시험
5.2 유사 실험 설계
5.3 도구 변수
_알고리즘 13 | 2SLS
CHAPTER 6 제어
6.1 조건부 무시가능성과 선형 처리 효과
6.2 고차원 교란 조정
_알고리즘 14 | LTE lasso 회귀
6.3 표본 분할과 직교 머신러닝
_알고리즘 15 | LTE를 위한 직교 머신러닝
6.4 이종 처리 효과
6.5 합성 제어
_알고리즘 15 | 합성 제어
CHAPTER 7 인수분해
7.1 클러스터링
_알고리즘 17 | K-평균
7.2 요인 모델과 PCA
_알고리즘 18 | 주성분 분석
7.3 주성분 회귀
_알고리즘 19 | 주성분 (lasso) 회귀
7.4 부분 최소제곱법
_알고리즘 20 | 주변 회귀
_알고리즘 21 | 부분 최소제곱법(PLS)
CHAPTER 8 데이터로서의 테스트
8.1 토큰화
8.2 텍스트 회귀
8.3 토픽 모델
_알고리즘 22 | 희소 데이터를 위한 PCA
8.4 다항 역회귀
8.5 협업 필터링
8.6 워드 임베딩
CHAPTER 9 비모수
9.1 의사결정트리
_알고리즘 23 | CART 알고리즘
9.2 랜덤 포레스트
_알고리즘 24 | 랜덤 포레스트(RF)
_알고리즘 25 | 경험적 베이지안 포레스트(EBF)
9.3 인과 트리
_알고리즘 26 | 인과 트리(CT)
9.4 반모수와 가우스 프로세스
CHAPTER 10 인공지능
10.1 인공지능이란 무엇인가?
10.2 범용 머신러닝
10.3 딥러닝
10.4 확률적 경사하강법
10.5 강화 학습
10.6 상황에 따른 인공지능
출판사 서평
아마존 수석 이코노미스트(부사장)의 노하우와 사례로 가득한 실무 중심의 비즈니스 데이터 과학
오늘날에는 머신러닝과 통계학, 데이터 기반의 사회과학 및 경제학과 같은 분야에서 끊임없는 지적 융합이 일어나고 있으며, 이러한 융합은 데이터 분석의 질을 높여줍니다.이 책은 최선의 데이터 분석 방법을 설명하기 위해 머신러닝과 통계학 그리고 경제학을 융합합니다. 머신러닝과 통계학으로 자동화 및 확장 방법을 배우고, 경제학에서 인과관계 및 구조 모델링을 위한 도구를 가져오며, 이러한 방법들이 비즈니스 의사결정과 어떤 관련이 있는지 설명합니다. ‘무슨’ 일이 일어났는지가 아니라 ‘왜’ 이런 일이 발생했는지에 초점을 맞추어 설명하기 때문에 다양한 모델의 핵심 개념을 쉽게 이해할 수 있습니다. 저자가 학생들을 가르치며 얻은 노하우와 이베이, 마이크로소프트, 아마존에서 경험한 사례를 여러분의 실무에 적용해보세요!
주요 내용
● 비즈니스 의사결정에 필요한 통계학, 경제학 이론과 머신러닝 알고리즘
● 텍스트 분석, 가격 결정 및 수요 추정, A/B 실험, 고객 행동 분석의 사례
● 머신러닝 도구를 사용하여 비즈니스 의사결정을 내리는 방법
● 인공지능으로 비즈니스 문제를 해결하는 방법
출처: https://plmis.tistory.com/1330 [맵으로 풀어가는 디지털혁신스토리텔링:티스토리]
-
비즈니스 데이터 과학
맷 태디
아마존 부사장. 2008년부터 2018년까지 시카고 대학교 부스 경영대학원에서 계량경제학 및 통계학 교수로 재직하면서 데이터 과학 커리큘럼을 개발. 마이크로소프트의 수석 연구원(Head of Economics and Data Science, Business AI)과 이베이의 연구원(Research Fellow)을 포함하여 다양한 산업 분야에서 일한 경험이 있다.
본 도서는
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
이 책은 실무자를 위한 비즈니스에서 자주 언급되는 문제와 관련된 통계학, 경제학 개념 및 빅데이터 기술, 머신러닝 알고리즘에 대해 알려준다.

군더더기 없는 표지



Image from analytics Steps
통계분석, 머신러닝에 대한 관심이 높아지고 있다.
약 10년 전까지만 해도 고도의 전문지식이 필요했는데
이제는 보다 쉽게 다양한 분야에 쓰이고 있다.
우리는 비즈니스에 있어서 과연 어떻게 기여할 수 있을까?
전문가가 되기 위해 많은 노력을 들여 준비해왔다면
통계,선형대수, 미분적분학등의 수학적인 지식과
Hard skill(coding...), soft skill(communication...)이 필요하겠다.

Image from Anaytics Vidhya
이 책은 실무에 있어 필요한, 기본이 되어야하는 지식을 알려준다.
학부, 석사 시절에 배운 개념들을 비즈니스에 어떻게 적용시키는 것까지 다루어주니
무척이나 필요한 책이라고 말할 수 있겠다.
내용은 생각보다 어려울 수 있다.
전문용어와 개념을 설명하기 위한 추상적인 표현이 있기 때문이다.
그러나 해당 책에서는 그림 및 도표 등의 시각적인 예제가 포함되어 있어
무엇을 전하고자 하는지 이해할 수 있을 것이다.
시계열 분석, 비모수, 회귀, 정규화, 실험 등의 내용을 다루고 있으니
개념들을 비즈니스에 적용시키고 싶다면 읽어보는 것을 추천한다.
-
이 도서는 "한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
학부에서 배웠던 "데이터 과학" 강의를 마치 책으로 풀어놓아 설명하는 듯한 인상을 남긴 책입니다.
이론부터 실습까지 방대한 내용을 다루고, 일상 생활에서 주로 다룰 수 있는 예시들 (주택 & 생필품 가격) 등을 다루고 있고 Berkely Data Science 101 내용을 R 프로그래밍으로 다양한 각도에서 탐독할 수 있습니다.
수식 등이 많이 나와서 익숙치 않는 분께는 초반에 읽기 어려울 수 있는데, 조금 익숙해지는 시간이 필요할 것입니다. (괜찮습니다, 저도 그랬거든요 :])
데이터 사이언스를 비즈니스 필드에서 어떻게 활용하는지 입문하고 싶다면 천천히 시간을 들여 읽어보시기를 추천합니다.
-

"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
이 책은 인공지능 개발자에게도 필요한 책이겠지만, 개인적으론 기획가에게 매우 필요한 책이라고 생각된다. 서비스에 필요한 개념들도 들어있어 고객사들에게 좀 더 좋은 방향으로 나아갈 수 있도록 도와줄 수 있게 한다.
베이지안, 정규화 등의 기본적인 개념부터 시작하여 인공지능을 접목시키는 방법까지 아낌없이 상세하게 설명한다. 다만 어느 정도의 기본기는 있어야 제대로 이해하기 쉽다. 수학적인 수식들이 많이 들어가 있기 때문에, 수학에 대한 기본기가 있는 사람들이 보게 되면 더욱 더 많은 통찰력을 얻어 가지 않을까 생각된다.
또한 마이크로소프트와 아마존에서 실제 사용했던 사례들도 포함되어 그들의 생각과 방향성을 쉽게 접할 수 있다는 것이 매우 장점이라 생각한다.
-
빅데이터, 데이터분석, 인공지능이 대세가 되며 비전공자들도 코딩을 배우기 시작한다. 파이썬 또는 R을 가지고 분석을 하는 사람들도 하나둘 늘어나고 대학교는 물론 학원에서도 이를 가르치는게 많아지고 있는 상황이다. 이런 흐름은 자연스러운것은 인정하나 무언가 무턱대고 이걸 배우면 나도 실력이 늘어나서 전문가가 될수있다고 자신하는 분위기에는 크게 긍정하지 않는 상황이다.
개인적으로 현재 인공지능 기술은 능력이라고 생각한다. 코딩만 잘하면 데이터 분석을 잘하고 인공지능을 다루는 전문가가 된다는 것이 아니라는 말과 같다. 데이터분석과 인공지능과 관련된 코딩은 그걸 구현해낼수 있는 능력이지 실제 결과 해석이나 추론은 또 다른 도메인이나 배경지식이 필요하다고 생각한다.
실제로 코딩을 잘 하더라도 분석과정에서 어떠한 의사결정을 내리는 데에 정말 많은 지식과 근거가 필요하다는 것을 실습으로든 대회로든 다양한 분석과제를 하면서 잘 느껴지고 있고, 그렇기에 이런 다양한 지식을 배워야한다는게 느껴져 이 부분을 끊임없이 공부하다보니 이 분야가 절대로 녹록치 않다는것이 잘 느껴지는 요즈음이다.
이 책은 그 부분을 중요하게 캐치해서 전반적으로 설명을 하고 있다. 애초에 책에 대놓고 이 책은 R을 배우기 위해 서술한 책이 아니라고 적혀있다. 비즈니스 데이터 과학이란 내용에 맞게 통계학과 경제학 그리고 거기에 필요한 약간의 인공지능을 더불어서 설명을 하고 있는 것이다.
그렇기에 일반적인 인공지능 서적과 차별점이 바로 드러나게 된다. 물론 인공지능에 대한 이론도 들어가고 코드도 있고, 그와 관련된 실습도 적혀있지만 이에 대한 결과를 해석하고 어떤식으로 받아들이고 추론하는지에 대한 과정이 추가적으로 들어간게 꽤 있다. 왜 이런 과정에서 이런 식의 내용으로 추론을 했는지 그 근거를 여러 수식과 경제학이론, 통계 공식등으로 확인하면서 접근을 하게 되는것이다.
이전까지 다른 책들은 그저 가볍게 혹은 참고정도로 보여주는게 전부였다. 통계도 베이즈 정리나 정확도, 정밀도 등을 계산하는 정도로 가볍게 접근하는게 많았기에 이 책도 그렇다고 생각했지만 진짜로 비즈니스 이론과 그와 관련된 공식을 보여주니 그깊이가 다르다라는게 많이 느껴지기도 헀다.
그렇기에 이 책을 추천하기 위해서는 가벼운 난이도로 접근하기는 어렵다고 느껴진다. 마치 정답이 나온 공식처럼 쭉 이어서 본다기 보다는 이 전체적인 추론과정을 정리하고 이를 알고리즘처럼 기억하거나 도식화하여 프로세스 단위로 기억하는 것이 가장 좋아보인다. 따라서 데이터분석을 입문하는 사람보다는 스킬을 막 배우고 난다음 어떤 분야에 활용이 가능한지, 어떻게 실전에 사용할수 있는지 궁금한 사람들에게 이 책을 추천하고 싶다.
-
데이터를 기반으로 의사 결정을 하는 과정을 자세히 설명하고 있는 책입니다.
데이터 과학을 공부하다 보면 학습한 기법들을 어느 상황에 적용해야 하는지 쉽게 감이 잡히지 않는데, 저자의 경험으로 상황에 맞게 문제를 해결하는 방법을 설명하고 있어 데이터 과학을 공부하고 계신 분들이라면 많은 도움이 될 거라 생각합니다.
특히 이 책이 흥미로웠던건 비즈니스 의사결정이 필요한 상황(사용자 분류, AB 테스트 등)을 먼저 제시하고 데이터를 분석하는 과정을 소개하고 있다는 점이였습니다.
보통의 데이터 과학 책들은 분석 알고리즘에 초첨을 두고 있는데, 이 책은 데이터 분석의 목적에 중점을 두고 있어 데이터를 여러 관점으로 바라보고 분석 기법을 선택하는 힘을 기를 수 있게 도와줍니다.
다만, 일정 수준 이상의 수학적 지식과 데이터 분석 기법을 알고 있어야 이 책을 이해할 수 있을 것으로 생각됩니다.
한빛미디어의 “핸즈온 머신러닝”이나 “데이터 과학을 위한 통계”을 먼저 보시고 읽으시길 권합니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
-
한빛미디어에서 <비즈니스데이터과학>이 지난 6월말에 출간되었습니다. 이 책은 기업 경영과 실무에 있어서 자주 맞닥뜨리는 실제 문제를 사례로 들면서 데이터 과학을 어떻게 적용하고 풀어나가는지를 매우 이해하기 쉽게 풀어주는 책인데요. 점차 기업 경영에 있어서 데이터 기반의 의사결정이 중요해짐에 따라 데이터 과학의 중요성은 커져만 가고 있습니다. 저도 주변 지인들이 전공 선택과 관련하여 질문을 받을때마다 경영학과 통계학을 함께 공부하라는 조언을 많이 하고는 합니다. 또는 프로그래밍과 경영을 선택하라고 할 때도 있고요.
이러한 이유는 바로 기업에서 의사결정이 데이터 기반으로 이루어지고 있기 때문입니다. 예전에는 감으로 무언가 의사결정을 했다면 이제는 더이상 그런 시기는 지났다고 할 수 있습니다. 하지만 문제는 경영학을 전공한 사람이 굳이 통계나 프로그래밍을 복수전공하지 않는 이상, 경영학을 전공한 사람에게 데이터과학에 관한 진입장벽은 매우 높다고밖에 할 수 없습니다.
이러한 어려움을 극복하고, 경영학전공자나 기업 실무자가 조금이라도 쉽게 데이터 과학에 입문할 수 있도록 돕는 책이 바로 <비즈니스데이터과학>이라고 할 수 있습니다. 10년전만하더라도 데이터과학이나 머신러닝, 인공지능은 특수 분야에서만 활용되거나 대학원 석박사들의 연구 주제일뿐이었습니다. 그러나 이제는 다양한 분야에서 널리 적용되고 있고, 특히 실무에서도 많이 활용됩니다. 이전에는 전문가만이 관련 데이터에 접근할 수 있었지만 지금은 누구나 쉽게 빅데이터에 접근할 수 있게 되었습니다.
그러나 접근은 가능했지만, 여전히 어렵게만 느껴지는 것은 사실입니다. 수많은 오픈소스들이 넘쳐나지만, 그것조차 어렵게 느끼는 문과생들이 수두룩 합니다. <비즈니스데이터과학>의 저자 맷 태디는 시카고 대학교에서 강의하던 경험을 살려서 기본적인 통계학 개념부터 데이터과학을 위한 머신러닝의 핵심 개념까지 매우 상세하게 다루고 있습니다. 따라서 이 책을 통해서 수많은 기업의 실무자들이 데이터 엔지니어로서 성장하는데 작은 발판이 될 것임을 믿어 의심치 않습니다.
-
한빛미디어 '나는 리뷰어다' 활동을 위해서 책을 제공받아 작성된 서평입니다.

0. 소개
Big Data & Machine Learning / Deep Learning이 세상의 빛을 본지가 꽤 되었지만, 여전히 뜨거운 관심을 받고 있습니다.
앞으로도 이런 관심은 대체할 만한 새로운 개념이 나오기 전까지는 계속될 것입니다.
Big Data & Machine Learning / Deep Learning이 관심을 받게 된 이유 중에 하나가 누구나 쉽게 접근할 수 있는 다양한 도구들이 많이 있기때문이기도 할 것입니다.
손쉬운 접근성에 힘입어 과학, 공학 분야 뿐만 아니라 의학, 미술, 정치, 경제 등에 이르기까지 매우 다양한 분야에서 훌륭한 역할을 수행하고 있습니다.
이 책은 특별히 비즈니스 분야에 사용되는 사례를 예를 들어서 설명하고 있습니다.
저자는 이 분야에서 매우 다양한 서술활동과 교수 활동을 한 사람으로써 데이터 과학 분야의 커리큘럼을 개발한 노하우가 고스란히 이 책에 녹아들어 있다.
이 책의 아쉬운 부분으로는 먼저, 통계학적 개념이 많이 나옵니다. 뿐만 아니라 복잡하고 다양한 수식 또한 많이 등장합니다.
이런 부분에 배경지식이 없는 분들은 쉽게 읽여지지 않을 것입니다.
모든 예제들은 R을 사용하고 있어서 R을 모르는 독자들은 간단하게 R을 학습하여야 예제들을 이해할 수 있습니다.
그리고, Machine Learning / Deep Learning에서 익히 들어 알고 있는 대략적인 개념만 알고 있는 기법들의 수학적인 배경을 자세히 설명하고 있는데
이것을 원한 독자들에게는 반가울 수 있지만, 다른 분야에서 이 분야로 입문하려는 독자들에게는 다소 난해할 수 있습니다.
추상적인 개념이 많고, 책이 전체적으로 어려운 느낌이 없지 않아 있어서, 탄탄한 수학적/통계적 배경 지식이 없으면 쉽게 읽을 수 없을 것 같다는 느낌을 줍니다.
1. 구성
Chap 1 들어가며
- 첫번째 Chap에서는 Machine Learning에 학습에 필요한 기본적인 내용들과 개념들(Graph , Big Data , Machine Learning, R , Package , 도구 등)에 대한 소개를 합니다.
Chap 1 불확실성
- 통계학적인 불확실성을 다루는 통계적 기법들에 대해서 이야기 합니다.
- 귀무가설 , 대립가설 , Bayesian 추론 등에 대해서 다룹니다.
Chap 2 회귀
- Machine Learning 분야의 한 분야인 회귀(Regression)에 대해서 논의합니다.
- 확률분포, Logistic Regression, 편차 / 가능도 , 회귀 불확실성에 대해서 다룹니다.
Chap 3 정규화
- Overfitting을 막기위한 방법 중 하나인 정규화 정규화(Regularization)에 대해서 논의합니다.
- 교차검증(CV, Cross Validation) / Lasso 등에 대해서 다룹니다.
Chap 4 분류
- Machine Learning 분야에서 회귀와 함께 많이 사용하는 분류(Classification)에 대한 이야기를 합니다.
- 다양한 분류 알고리즘 소개와 실제 많이 사용하는 기법들에 대한 소개를 합니다.
- KNN , 확률 , ROC AUC , Logistic Regression등에 대해서 다루며, 분산 & Big Data 분야에서 많이 사용하는 Framework들에 대한 소개도 곁들여 하고 있습니다.
Chap 5 실험
- 특정 조건 / 변수가 결과에 미치는 영향을 분석하기 위한 다양한 실험 방법론에 대해서 논의합니다.
- 대조실험 , AB 테스트(무작위 대조 실험) , 유사 실험 설계 등에 대해서 다룹니다.
Chap 6 제어
- 실험에서 중요한 조건 / 변수들을 정확하게 제어하는 방법들에 대한 내용입니다.
Chap 7 인수분해
- 좋은 결정을 내리는 필요한 고차원의 데이터를 저차원으로 압축하는 방법인 차원 축소에 대해서 다룹니다.
- 인수분홰( x에 대한 기대값을 적은 수의 인수의 합으로 나누는 방법 ) , Clustering , PCA , 부분 최소 제곱법 등에 대해서 논의합니다.
Chap 8 데이터로서의 텍스트
- Text Data를 Machine Learning에 사용하는 방법론들에 대해서 논의합니다.
- Tokenization , 텍스트 회귀 , Topic Model, 다항 역회귀 , Word Embedding 등에 대해서 논의합니다.
Chap 9 비모수
- Tree Based 방법들에 대해서 이야기 합니다.
Chap 10 인공지능
- DNN(Deep Neural Network)을 응용한 다양한 Deep Learning 기법들에 대한 이야기입니다.
2. 대상 독자
Data 기반 회사에서 Data Scientist로 일하려는 사람뿐 아니라, Data Science 기술을 습득하려는 과학자, 비지니스 전문가, 엔지니어 등에게 초점을 맞추고 있습니다.
데이터 과학자들은 비즈니스에 중요한 결정을 내리기 위한 요소들에 대한 Data를 수집하고 그 Data속에서 Insight를 도출하는 일을 하게될 것인데, 이들을 위한 수학적 , 통계학적 배경 지식을 전달해 줄 것입니다.
'무슨 일'이 '왜' 일어났는지를 Data를 기반으로 설명할 수 있어야 합니다. 다시 말해, Data와 결과 사이의 인과관계를 해석할 수 있어야 합니다.
이 책은 이를 위한 비지니스 Data Science의 핵심요소를 선별하여 소개해 주고 있습니다.
또한, 다른 분야의 전문가들이 데이터 과학 기술 분야에 입문하기 위한 좋은 입문서의 역할도 할 수 있을 것이다.
-
이달에 접하게 된 책은 <비즈니스 데이터 과학>이다. 한빛 덕분에 다양한 책들을 보게 된다.
우선 시작 부분(14쪽)에서 표기에 대한 안내를 표로 깔끔하게 정리해줘서 책을 읽는데 도움이 되었다.

회귀, 분류, 군집화, PCA, 텍스트 데이터 처리, 트리기반 알고리즘 그리고 마지막으로 인공지능에 대한 기본적인 설명까지 코드와 수식, 이미지를 적절히 넣어서 잘 보여주고 있다. 물론 R을 사용해서 파이썬 기반인 나에게 당혹감을 선물한 것은 덤....이지만, "이 책은 R 사용법을 배우기 위한 책이 아니다....이 책은 데이터 과학을 수행하는 방법에 관한 책이다" 라는 말에 힘을 얻고 읽어 보았다.
1장의 불확실성, 5장의 실험, 6장의 제어라는 제목이 좀 특이하게 느껴져서 그 부분을 먼저 살펴보았다. (나머지 제목들은 너무나 익숙한 제목들이다)
아, 통계에 대한 기본 지식이 없으면 1장부터 읽기가 버겁다^^(그래서 2.4부터 읽고 다시 돌아오기를 권하기도 한다) 먼저 빈도주의 관점에서 불확실성에 중점을 두고 부트스트랩을 이용한 리샘플링, 가설 검정, 거짓 발견 비율(FDR, false discovery rate) 의 조절에 대해 설명해주고, 다음으로는 빈도주의에 비해서는 비즈니스 데이터 과학에서 더 큰 역할을 하고 있으며, 반복적인 시행 보다는 주관적인 믿음을 바탕으로 한 베이지안 추론에 대해서 설명한다.
앞장에서 설명한 회귀, 분류의 경우 과거 데이터에서 패턴을 발견해 내고 있고, 이런 패턴은 미래가 대부분 과거와 비슷하다는 가정 하에서 미래를 예측하는 데 유용하게 사용된다. 그런데 비즈니스나 경제 시스템에서는 현재의 행동이 미래를 바꾸기 때문에 과거와는 다른 미래를 예측할 수 있어야 한다며 [5장 실험]을 시작한다. 반사실적인 예측, 즉 '만일 ~라면'이라는 질문에 대해 대답하길 원한다. 가격을 P0 대신 P1로 변경하면 매출이 어떻게 달라질까에 대해 답하는 문제이다. 이 방법으로 무작위 대조 시험에 대해 설명한다. 다음으로는 두 가지 유사한 상황에 대한 시나리오를 만들어 실험을 한다. "비록 다른 장소지만 두 장소의 처리 전 차이를 모델링 할 수 있드면 처리 후 변화에 대한 인과적 해석을 할 수 있지 않을까?" 하는 가정에서 만든 시나리오(이중차분 분석), 사회보장제도 혜택을 아쉽게 놓치는 사람(처리군)과 간신히 자격이 되어서 혜택을 보는 사람(대조군)의 두 그룹을 만들어 비교하는 시나리오(회귀불연속성 추정)이다. 그리고 마지막으로 '도구 변수'의 개념으로 설명한다.
[6장 제어] 안타깝게도 현실에서는 '실험' 없이 과거 데이터를 기반으로 향후 활동에 대해 결정을 내려야만 한다. 그래서 처리를 설정하는 실험을 하는 대신 과거에 무슨 일이 있었는지를 '관찰'한다. 이 장에서는 어느 정도 믿을 수 있다고 알려진 방법과 원칙, 머신러닝 도구 등을 사용해서 분석하는 방법을 다루고 있다. 조건부 무시가능성과 선형처리 효과, 고차원 교란 조정, 표본 분할과 직교 머신러닝, 이종 처리 효과, 합성 제어 등에 꽤 많은 분량을 할애한다. 이 부분은 사실 좀 더 시간을 두고 다시 읽어봐야 할 것 같다.
마지막으로 한 가지 웃음 포인트는 '인수분해'라고 하는 아련한 단어였다. 얼마만에 들어보는 단어인지^^ 중고등학교 수학 시간에 거의 기계적으로 인수분해를 했었는데, 7장을 시작하며 써있었던 "이 장에서는 각 x에 대한 기댓값을 적은 수의 인수의 합으로 나누는 다양한 인수분해 방법을 살펴본다"는 문구를 읽는 순간 머릿속에 어떤 그림이 그려지면서 머리가 단순해지는 신기한 기분을 느꼈다.
통계에 대한 지식이 없거나 통계용어에 익숙하지 않은 사람들은 [10장 인공지능]을 먼저 읽고 앞부분을 봐도 좋을 것 같다.
한빛미디어 <나는
리뷰어
다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
-
이 책은 제목그대로 비즈니스 분야에서 자주 언급되는 실제 문제를 예로 들어 빅데이터 기술과 머신러닝 기법을 소개하고 있다
기본적인 통계학 개념부터 머신러닝 알고리즘까지 핵심적인 내용들을 다루고 있어서 데이터 과학 초심자가 읽기에도 매우 좋은 책이다
이 책에서 다루고 있는 불확실성, 회귀, 정규화, 분류, 실험, 제어, 인수분해, 데이터로서의 텍스트, 비모수, 인공지능 챕터에서 각각의 이론에 대해서 상세히 설명하고 비즈니스 관점에서 어떻게 이론을 적용해서 데이터를 다루어야 할지 예를 들어 자세히 설명하고 있다
또한 데이터를 사용하여 비즈니스를 운영하는데 도움이 되는 흥미로운 내용을 모두 모았다
통계, 머신러닝, 경제학에서 나온 핵심 원칙과 모범 사례를 제시하고 다양한 실제 데이터 분석 예제로 실습을 통해 학습한다
이 책은 데이터 과학의 모든 것을 알려주고 있지는 않지만 데이터 과학의 전반적인 내용과 흐름에 대해서 파악할 수 있게 도움을 주고 있다
비즈니스의 성공을 위해서 데이터 과학은 이제 매우 중요한 요소 중 하나이다
정의된 데이터 과학이론들과 분석하기 위한 수많은 도구들 그리고 머신러닝도 많은 발전을 이루어나가고 있는 시점에서 비즈니스 데이터 과학에 대한 이해는 필수이다
그 시작을 이 책으로 시작해보기를 추천해본다
-
이 책은 비지니스 데이터 과학에 필요한 도구를 파악하기 위해 모든 분야를 활용해야한다고 한다.
사실 분석을하는데 있어 한가지의 학문으로만 보기에는 세상일이 단순하지만은 않은게 사실이다.
하지만 이 책에서 말하는 것은 요즘 한 플랫폼을 서비스할 때 한가지의 언어, 하나의 기술만으로 서비스 하지않듯이
데이터분석을 할 때도 하나의 방법만으로 분석하지 않고 상황에 따라 더 효율적인 방법을 제시하여
상황에 맞는 분석법을 제시하여 분석할 수 있도록 도와주는 것이다.
주요 내용으로는
1. 통계학, 경제학, 머신러닝 알고리즘을 이용한 비즈니스 의사결정에 필요한 이론 설명
2. 텍스트 분석, 가격 결정과 수요 측정, A/B 실험, 고객행동 분석을 통해 다양한 사례 탐구
3. 머신러닝을 사용한 의사결정 방법을 제시하여 비즈니스 의사겨정 방법을 소개
4 . 인공지능으로 비즈니스 문제를 해결하는 방법을 탐구하여 비즈니스 문제 해결 방안
이 기술되어 있다.
* 대상 독자
이 책의 대상 독자는 데이터 과학 기술을 습득하려는 과학자, 비즈니스 전문가, 엔지이어 등이다.
수학, 프로그래밍, 비즈니스를 배운 다음 데이터 과학에 진압할 수 있도록 사전지식이 상당이 필요로 한다.
이 책은 수학에 대한 기초 지식과 최소한의 컴퓨터 프로그래밍 경험이 있는 사람이라면 누구나 읽을 수 있다.
이 책에서는 대부분의 예제 스크립트에서R을 사용하므로 기본 사전지식으로 R도 필수항목이다.
이 책은 지저분한 데이터를 비즈니스 정책과 직접적인 관련이 있는 유용한 정보로 빠르게 전환할 수 있는 방법을 제공한다.
이 책에서 말하는 기본적인 수학이라는 것은 대학수학에 해당하는 선형대수학, 이산수학 등의 학문을 이해할 수 있을정도의
수학적 지식을 요구하고 있으며 위에서 말했듯이 기본적인 개발지식에 R언어를 사용할 수 있어야 이책을 이해하며 학습할 수 있다.
어느 다른책들과 드람없이 예제와 설명, 그에따란 분석방법 등이 자세하게 설명하고있어 차근차근 따라가면서 학습할 수 있다.
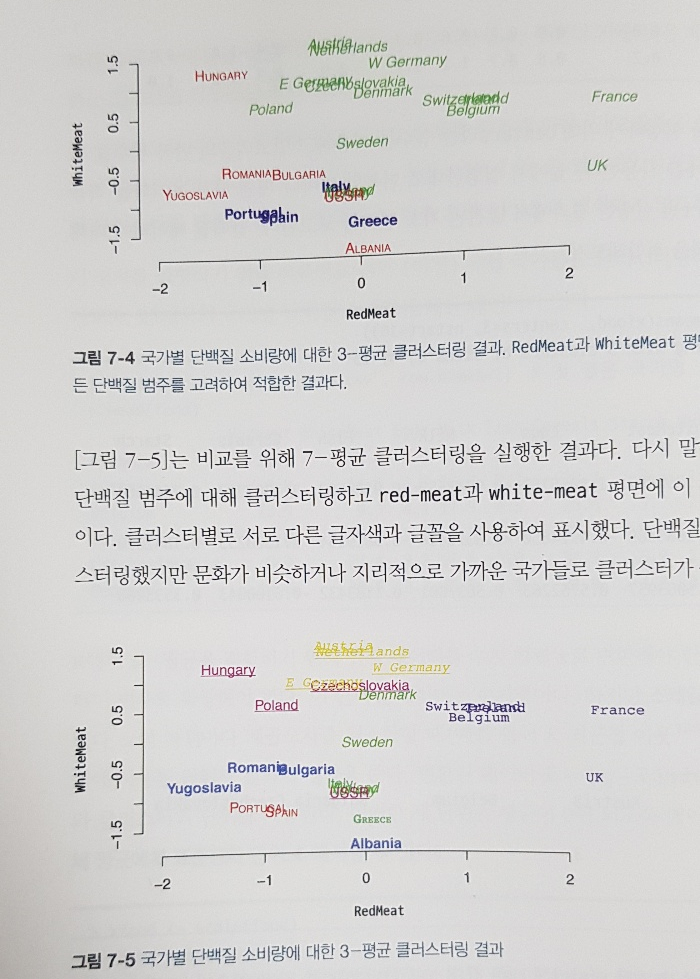
예시 그래프들이 컬러로 되어있어 글자가 겹쳐서 구분못하는 일은 없을것이다.
해당 도서의 예제소스 링크이다.
https://github.com/TaddyLab/bds
한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
-
-
내용이 없습니다.
-
내용이 없습니다.